14 изображений с подробной расшифровкой дизайна инвентаря системы флэш-продаж крупных производителей. Не все инвентари могут поддерживать высокий параллелизм!
Автор: Бинхэ Планета: http://m6z.cn/6aeFbs Блог: https://binghe.gitcode.host Адрес получения исходного кода: https://t.zsxq.com/0dhvFs5oR
Ускоряйтесь, растите, прорывайтесь, помогайте другим и достигайте себя.
Привет всем, я Бинхэ~~
Я считаю, что многие друзья раскупали продукты крупных производителей на флэш-распродажах, но задумывались ли вы когда-нибудь над таким вопросом: как спроектировать инвентарь продуктов в сценарии с высоким уровнем параллелизма и большого трафика, таком как флэш-продажи? Как мы можем выдержать мгновенный высокий одновременный трафик?
Есть также много друзей, у которых в резюме указана система флэш-продаж, когда они идут на собеседования. В это время интервьюер обычно задает такой вопрос: как устроена ваша система флэш-продаж? Вы должны знать, что если инвентарь системы флэш-продаж просто спроектирован в соответствии с инвентарем обычных товаров, он не сможет поддерживать мгновенный высокий одновременный трафик.
Сегодня Бинхэ расскажет вам, как система флэш-продаж крупных производителей проектирует инвентарь, основываясь на своем многолетнем опыте участия в проектировании инфраструктуры флэш-продаж крупных производителей, а также на своем опыте обеспечения стабильности ядра. ссылки для вычетов заказов и вычетов запасов для заказов, размещенных во время крупных рекламных акций. Конечно, большая часть проектирования архитектуры, реализации кодирования, развертывания и онлайн-контента также хранится в колонке «Система Seckill с высоким параллелизмом» на Glacier Technology Knowledge Planet.
Вы можете перейти по ссылке: https://t.zsxq.com/iG6Fq, чтобы узнать «Система Seckill с высоким параллелизмом», купоны есть в конце статьи.
1. Предисловие
Оптимизация операций чтения и записи базы данных системы флэш-продаж — это не просто вопрос репликации «главный-подчиненный», а также подбазы данных и подтаблицы. Вместо этого необходимо начать с бизнес-сценариев мгновенного высокого параллелизма и большого трафика, уникальных для флэш-продаж, и оптимизировать базу данных в соответствии со сценарием.
Для сценариев флэш-продаж ключевым моментом является поддержка мгновенного высокого уровня параллелизма и большого трафика. Когда большое количество пользователей спешат покупать продукты и размещать заказы, они часто вызывают интерфейс для запроса и обновления запасов продуктов. нам нужно повысить производительность чтения и записи базы данных.
С точки зрения конкретного дизайна, инвентаризация товаров предназначена для разделения на базы данных, таблицы и сегменты, так что инвентаризация товаров больше не хранится в одной базе данных, а расширяется на несколько баз данных, и в каждой базе данных инвентаризация товаров. Запасы разбиты на ведра. При этом на уровне кэша запасы товаров также необходимо разбить на ведра.
2. Цели оптимизации запасов
До официального разделения товарных запасов на склады, столы и ведра,,Давайте сначала определим цели оптимизации запасов.,То есть цель проектирования подбаз данных, таблиц и сегментов.,Это будет более целенаправленным в последующих реализациях. здесь,В основном я разделяю цели оптимизации запасов на шесть пунктов::Проектирование подбазы данных, проектирование подтаблиц, проектирование подсегментов, проектирование кэша, проектирование согласованности и проектирование совместимости.,Как показано ниже.
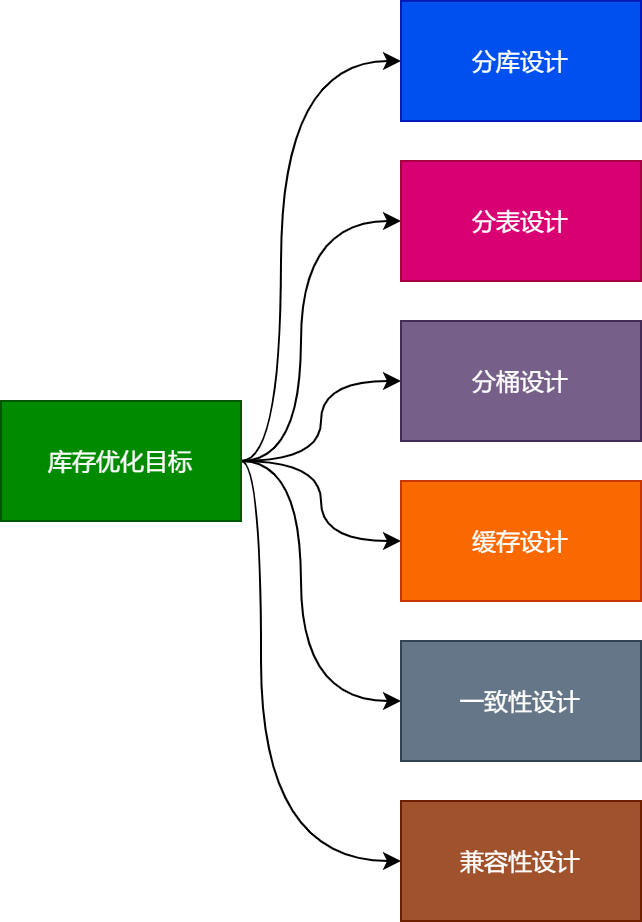
- Разделите инвентарь в соответствии с дизайном продуктов флэш-распродажи: чтобы запасы одного и того же продукта флэш-распродажи можно было направить на одну и ту же базу. данные для обработки.
- Разделите запасы в соответствии с дизайном продуктов мгновенной распродажи: чтобы запасы одних и тех же продуктов мгновенной распродажи можно было направить в одну и ту же базу данных, а затем дополнительно разделить запасы в соответствии с идентификатором продукта.
- Инвентаризация ведра в соответствии с дизайном продуктов флэш-распродажи: для системы флэш-распродажи,Основным улучшением подбазы данных и подтаблицы является возможность одновременной обработки нескольких операций флэш-продаж.,Дизайн группировки в основном решает проблему параллельной обработки одного события флэш-продажи.
- В соответствии с таблицей инвентарной подбиблиотеки и схемой ведра.,План инвентаризации, соответствующий дизайну: план подбиблиотеки, таблицы и сегмента на основе инвентаризации.,Дизайн кэш-плана инвентаризации сегмента для товаров: данные инвентаризации сегмента в кэше будут удерживаться до фактического вычета запасов товаров в сегменте.,Для улучшения возможностей параллельной обработки system.
- Дизайн согласованности данных: между кэшем и базой Уровень согласованности данных основан на подбазе данных, дизайне таблиц и сегментов, а слабая согласованность достигается на уровне кэша, базы. Достичь строгой согласованности на уровне данных.
- Дизайн совместимости: для дизайна подтаблиц и ведер нового продукта.,Совместимость с предыдущим ассортиментом продуктов.,Может свободно переключаться в соответствии с простой конфигурацией.
3. Разработка подбазы данных и подтаблиц
При проектировании подбаз данных и подтаблиц здесь мы используем три реализации библиотеки (в реальных сценариях количество подбаз данных и подтаблиц можно гибко настроить в соответствии с конкретными потребностями. По умолчанию одна библиотека продуктов и). Для хранения инвентарной информации о товарах используются две библиотеки инвентаря. Они не зависят от таблицы продуктов и выполняют отдельную базу данных, таблицу и корзину.
- Библиотека продуктов. В процессе размещения заказов на мгновенную продажу основное внимание уделяется операциям чтения, таким как получение подробной информации о продуктах мгновенной продажи и т. д.
- Библиотека инвентаря: во время процесса флэш-заказа на продажу.,В основном основано на операциях записи,В основном для вычета запасов товаров в процессе заказа.,распределятьбаза давление письма данных.
Здесь необходимо отметить, что в реализованной нами системе флэш-продаж одна библиотека продуктов и две библиотеки инвентаря используются для реализации подбазы данных, таблиц и корзин для инвентаризации продуктов. В реальных сценариях вы можете спроектировать ее в соответствии с. актуальные потребности бизнеса, гибко настраивайте количество подбаз данных, таблиц и сегментов.
При разработке подбаз данных и таблиц для инвентаризации продуктов очень важным моментом является разработка ключа сегментирования. Так называемый ключ сегментирования предназначен для указания поля, через которое данные направляются в соответствующую базу данных и таблицу данных. При разработке ключа сегментирования системы флэш-продаж постарайтесь направить связанные операции в одной транзакции для одного и того же пользователя в одну и ту же базу данных, чтобы снизить транзакционные издержки операций между базами данных.
Принципиальная схема после разделения товарных запасов на склады и таблицы представлена на рисунке ниже.
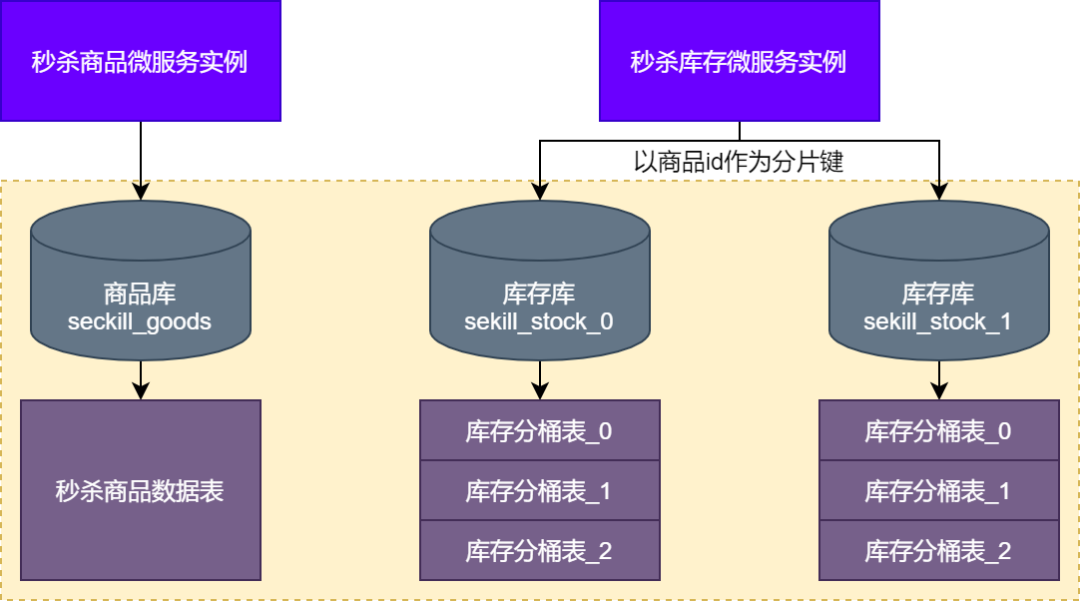
Видно, что для инвентаризации продуктов после разделения базы данных на таблицы она будет разделена на одну базу данных продуктов и две базы данных инвентаризации. В базе данных продуктов хранится информация о продуктах для мгновенной продажи, в основном в бизнес-сценариях, когда пользователи спешат покупать и размещать. В основном операции чтения.
В базе данных инвентаризации хранятся сегментированные данные инвентаризации, а в каждой базе данных инвентаризации хранятся три сегментированные данные инвентаризации. Данные в этих подбазах данных и таблицах можно гибко корректировать в соответствии с реальными потребностями.
Для подбазы данных и таблицы запасов продуктов в реальных сценариях сегментирование может выполняться на основе идентификатора продукта. Другими словами, ключ сегментирования, который мы здесь выбираем, — это идентификатор продукта, и запасы того же продукта будут перенаправлены в одну и ту же базу данных, и никаких операций между базами данных не будет.
4. Конструкция ведра инвентаря
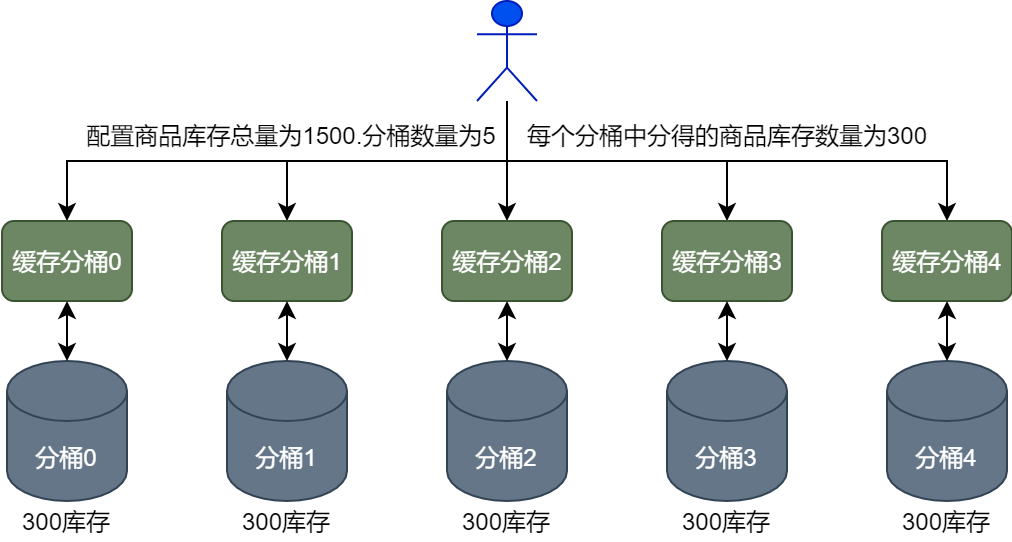
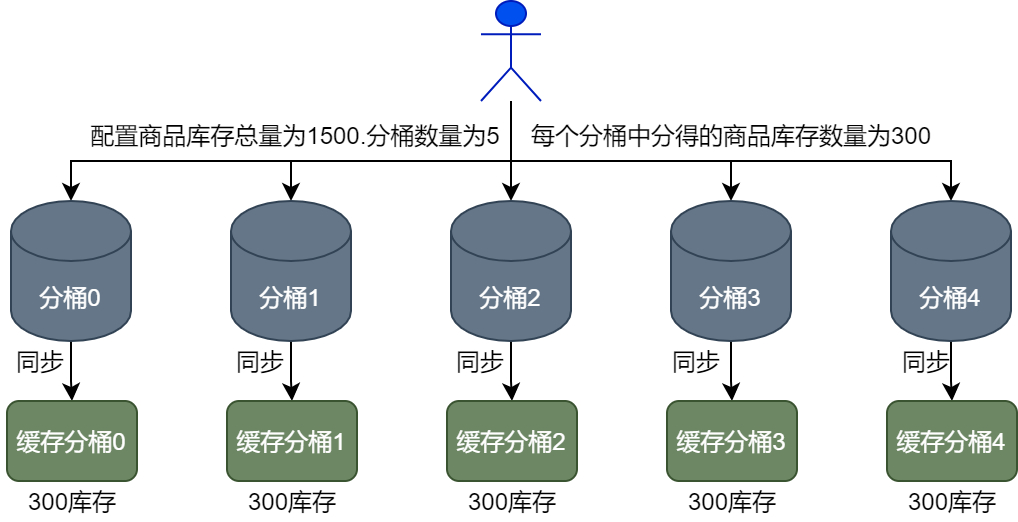
На основе подбазы данных и подтаблицы, чтобы еще больше повысить производительность одновременной записи в базу данных, инвентарь товаров может храниться в сегментах. Когда операторы настраивают информацию о запасах, они могут установить общий объем запасов и количество сегментов. Например, если 1500 продуктов должны быть распределены по 5 сегментам, каждому сегменту будет выделено 300 запасов продуктов, как показано ниже. Как показано на рисунке. .
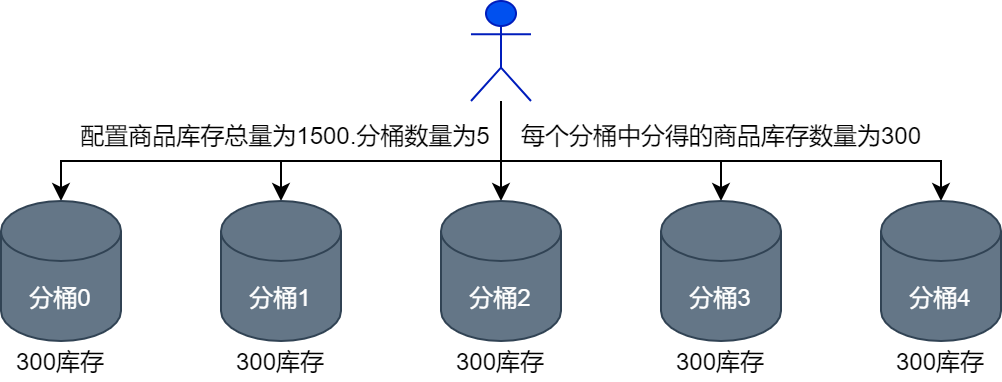
Таким образом, каждое ведро может нести часть давления записи, тем самым разделяя давление записи инвентаря продукта, так что база данных инвентаря системы флэш-продаж может иметь более высокие возможности одновременной записи.
Когда пользователь спешит разместить заказ, идентификатор пользователя будет моделироваться на основе количества сегментов для поиска соответствующего сегмента инвентаря. Например, если идентификатор пользователя равен 10001, а количество сегментов в текущем инвентаре установлено на 5. , то пользователь спешит разместить заказ. Когда текущий пользователь спешит разместить заказ, запрос на вычет запасов продукта будет перенаправлен в корзину 1, как показано на рисунке ниже.
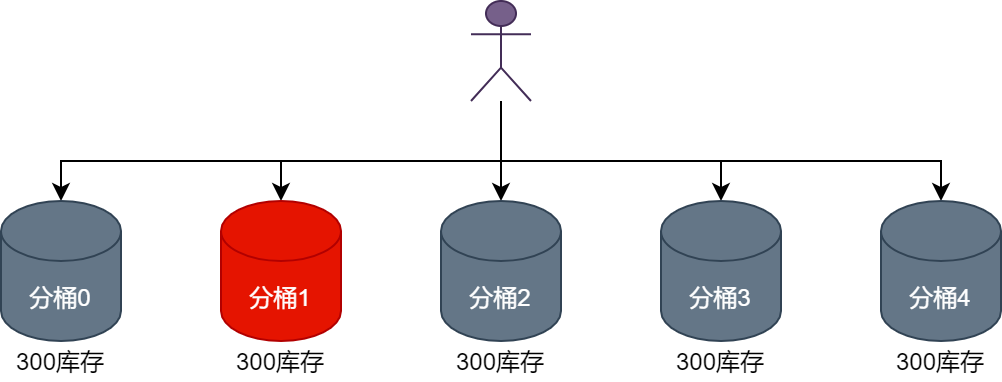
Когда пользователь с идентификатором пользователя 10002 размещает заказ, запрос на вычет запасов продукта будет перенаправлен в корзину 2, как показано на рисунке ниже.
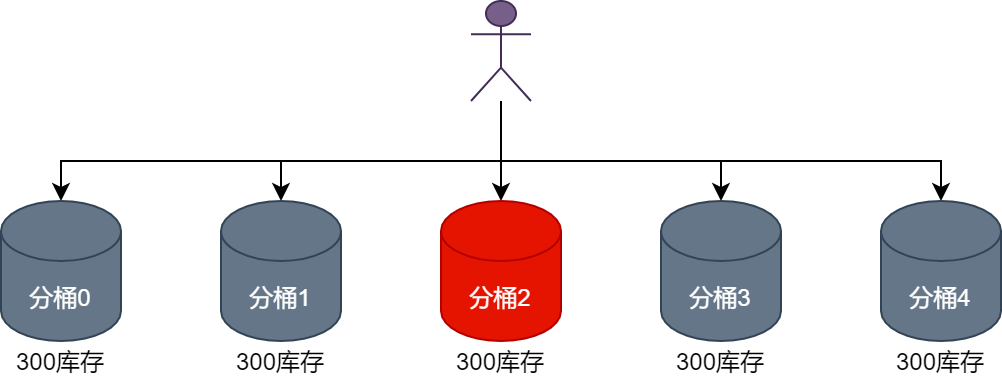
Видно, что когда пользователи спешат разместить заказ, запрос на вычет запасов продуктов будет перенаправляться в разные корзины, что может значительно уменьшить проблему конфликтов одновременной записи и повысить производительность одновременной записи при вычете запасов продуктов.
Здесь другая проблема заключается в том, что после того, как запасы продуктов разбиты на сегменты, в каждом сегменте хранится часть информации о запасах текущего продукта. Так как же определить общий запас продукта? На самом деле есть два варианта и решения этой проблемы.
- Первое решение — сохранить общий запас и количество продукта в корзине в таблице данных о продукте и сохранить текущую информацию о запасах в каждой корзине.
- Второе решение — выбрать основной сегмент среди нескольких сегментов для хранения общего количества товаров.
- Третье решение — сохранить общий запас и количество продукта в корзине в таблице данных о продукте, причем в каждом сегменте хранятся общие запасы текущего сегмента и доступные на данный момент запасы.
Принимая во внимание одновременные операции записи запасов продукта и последующий операционный персонал, возможно, потребуется скорректировать информацию о запасах продукта, здесь мы принимаем третий вариант, который заключается в сохранении общего запаса продукта и количества сегментов в продукте. таблица данных и каждая корзина. Храните в ней текущий общий запас товаров по сегментам и текущий доступный запас. Как показано ниже.
Когда операционный персонал настраивает запасы продукта, он сохраняет общий запас и количество продукта в корзине в библиотеке продуктов, а в каждом сегменте хранятся общие запасы и доступные запасы текущего сегмента.
5. Стратегия сокращения запасов сегмента
После того, как мы разложим инвентарь по отдельным таблицам и сегментам, в реальных сценариях в большинстве случаев трафик, направляемый в разные сегменты инвентаря, будет разным, что приведет к тому, что оставшийся инвентарь в разных сегментах инвентаря будет разным. Например, когда объем будет разным. пользователь с идентификатором 10001 спешит разместить заказ, он будет перенаправлен в корзину 1. Когда пользователь с идентификатором 10002 спешит разместить заказ, он будет перенаправлен в корзину 2.
Возможная ситуация: в корзине 1 в данный момент нет инвентаря, но есть в корзине 2. Так что же делать пользователю с идентификатором 10001? На данный момент мы можем рассмотреть три варианта:
Вариант 1: Спроектируйте механизм «борьбы» для корзин инвентаря, аналогичный платформе Fork/Join в Java. Если инвентарь в текущем корзине недостаточен, инвентарь в других корзинах будет «бороться» по определенным правилам.
Вариант 2: В каждом сегменте резервируется некоторый избыточный запас. Если в определенном сегменте недостаточно запасов, его можно позаимствовать из других сегментов.
Вариант 3: Пользователи, перенаправленные в разные сегменты инвентаря, увидят разное количество оставшегося инвентаря. Если инвентаря в определенном сегменте недостаточно, пользователям, перенаправленным в этот сегмент, будет напрямую предложено указать, что у него недостаточно ресурсов.
У этих трех вариантов есть свои плюсы и минусы. Рассмотрев сценарий мгновенной распродажи, мы в конце концов выбрали вариант 3. Вы должны знать, что в большинстве сценариев флэш-распродаж большое количество пользователей спешат купить ограниченное количество продуктов. В большинстве случаев все групповые товары будут распроданы мгновенно.
Существуют ли экстремальные ситуации, когда запасы в некоторых корзинах не могут быть распроданы? Нельзя сказать, что такой ситуации не бывает. Она может случиться, но вероятность крайне мала.
Если действительно существует ситуация, когда запасы в некоторых корзинах не могут быть распроданы, корзины инвентаря можно сократить вручную, а нераспроданные запасы в корзинах можно сжать в одно ведро. инвентарь не разделен на сегменты, все последующие запросы будут направляться в один и тот же сегмент инвентаря, и в конечном итоге инвентарь будет распродан.
Варианты 1 и 2 более сложны в реализации. Необходимо полностью продумать, как реализовать механизм конкуренции за инвентарь в сценариях с высоким параллелизмом и большим трафиком, и учитывать, что проблема перепроданности и недопроданности инвентаря не может возникнуть. Это, несомненно, связано с этим. Архитектура системы добавляет сложности.
В этом сценарии флэш-распродажи нет необходимости реализовывать План 1 и План 3. С другой точки зрения, для платформы и продавцов необходимо обеспечить возможность распродажи всех продуктов и согласованность данных. Для пользователей совершенно необходимо обеспечить строгую согласованность данных инвентаризации. Пока пользователь может видеть инвентаризацию в соответствующем сегменте, нет необходимости гарантировать, что пользователь может видеть строгую согласованность данных инвентаризации.
6. Кэширование и согласованность
Недостаточно выполнить проектирование корзины на уровне базы данных для инвентаризации товаров. Вы должны знать, что TPS одновременной записи одной строки MySQL составляет около 300~500, даже если мы выполняем дизайн корзины для товаров. , если мы разделим товары на базы данных, таблицы и корзины, если трафик вычета запасов системы флэш-продаж напрямую отправляется в базу данных. Даже если развернут кластер MySQL, предполагается, что ему будет трудно выдержать весь одновременный трафик. . Следовательно, нам также необходимо выполнить проектирование корзины для запасов продуктов в кеше.
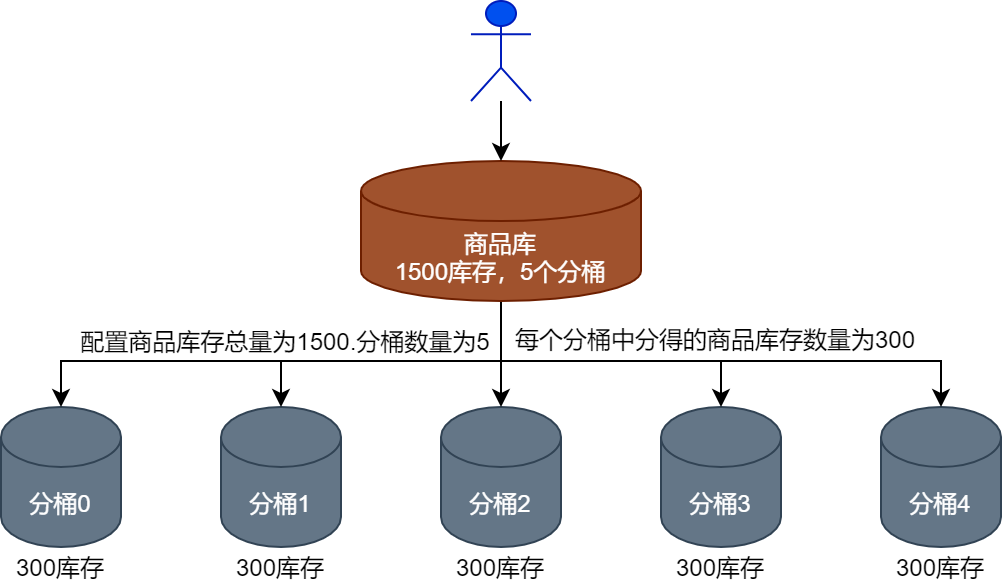
Структура распределения запасов продуктов на уровне кэша соответствует правилам проектирования сегментов на уровне базы данных. Например, если оператор хочет распределить 1500 продуктов по 5 сегментам, каждый сегмент кэша и сегмент базы данных будут содержать 300 элементов запасов продуктов. распределены, как показано на рисунке ниже.
Когда пользователь спешит разместить заказ, идентификатор пользователя также моделируется на основе количества сегментов для поиска соответствующего сегмента инвентаря. Сначала вычитаются запасы в сегменте кэша, затем размещается заказ и, наконец, определяются точки базы данных. вычтены запасы в бочках.
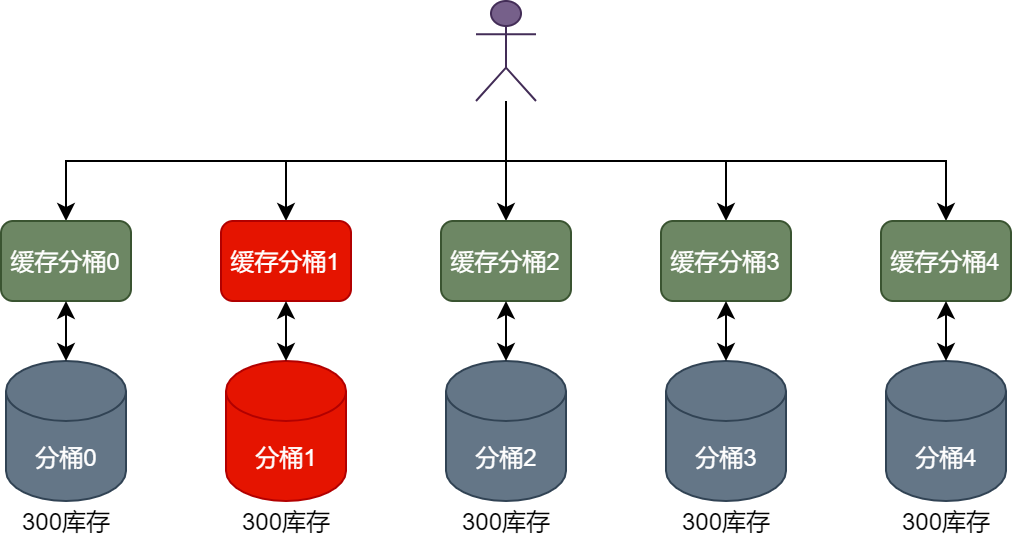
Например, идентификатор пользователя — 10001, а текущий объем корзины запасов установлен на 5. Когда пользователь спешит разместить заказ, запрос на вычет запасов продукта, когда текущий пользователь спешит разместить заказ, будет перенаправлен в корзину. 1, как показано на рисунке ниже.
В это время запрос пользователя с идентификатором 10001 на вычет запасов продуктов будет перенаправлен в сегмент кэша 1 для удержания запасов продуктов. Если удержание будет успешным, данные заказа будут созданы и сохранены, и, наконец, запасы будут в базе данных. данные из сегмента 1 будут вычтены.
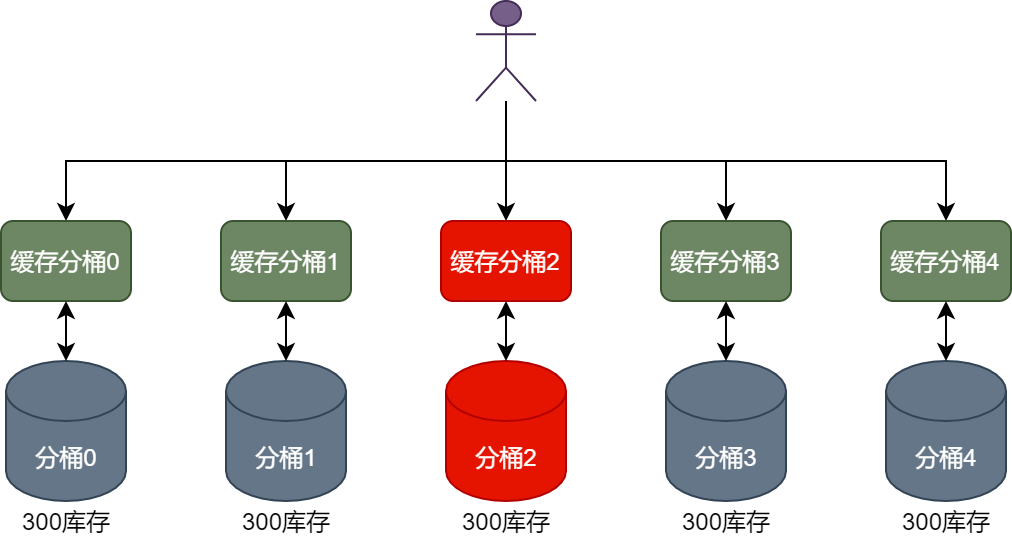
Если идентификатор пользователя равен 10002, а текущий объем корзины запасов установлен на 5, то, когда пользователь спешит разместить заказ, запрос на вычет запасов продукта, когда текущий пользователь спешит разместить заказ, будет перенаправлен в корзину 2. как показано на рисунке ниже.
В это время запрос пользователя с идентификатором 10001 на вычет запасов продуктов будет перенаправлен в сегмент кэша 2 для удержания запасов продуктов. Если удержание будет успешным, данные заказа будут созданы и сохранены, и, наконец, запасы в базе данных. данные из сегмента 2 будут вычтены.
Тут другой вопрос, как синхронизировать данные инвентаризации в бакетах в кеше с данными инвентаризации в бакетах базы данных? На самом деле конструкция относительно проста: когда оператор устанавливает или корректирует запасы продуктов и количество сегментов, рассчитанный запас продуктов будет записан в базу данных. После успешной записи данные об инвентаризации сегментов будут записаны в кэш. будет обновлен.
Инвентаризация сегментов продуктов в кэше поддерживает слабую согласованность, а инвентаризация сегментов продуктов в базе данных — строгую согласованность. Как показано ниже.
Когда оператор устанавливает запасы продукта и количество корзин, общий запас и количество корзин продукта будут храниться в таблице данных о продукте, а в каждой корзине хранятся общие запасы и доступные запасы текущего корзины.
После успешной установки данных инвентаризации продуктов в сегменте базы данных они синхронизируются с кешем. Правила инвентаризации сегментов продуктов в кэше такие же, как и в базе данных.
В то же время сегментированные данные инвентаризации в кэше поддерживают слабую согласованность, а сегментированные данные инвентаризации в базе данных поддерживают строгую согласованность.
7. Сбросьте настройки и настройте конструкцию ковша.
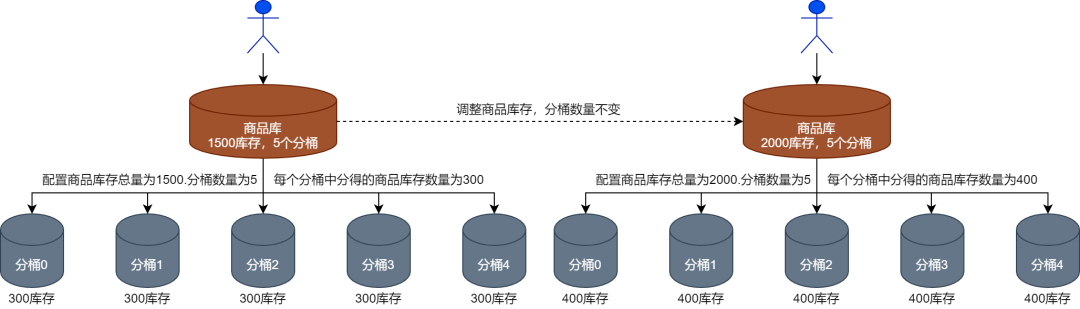
Операторы неизбежно будут корректировать информацию о запасах продуктов флэш-продажи. Например, первоначальный запас продуктов составляет 1500, но позже они хотят скорректировать его до 1000 или 2000. Таким образом, система флэш-продаж должна поддерживать операторов для динамической корректировки инвентаря флэш-продаж. продажа продукции.
Таким образом, запасы продуктов мгновенной распродажи можно корректировать в режиме реального времени. Когда операторы корректируют запасы, возникают три ситуации, как показано ниже.
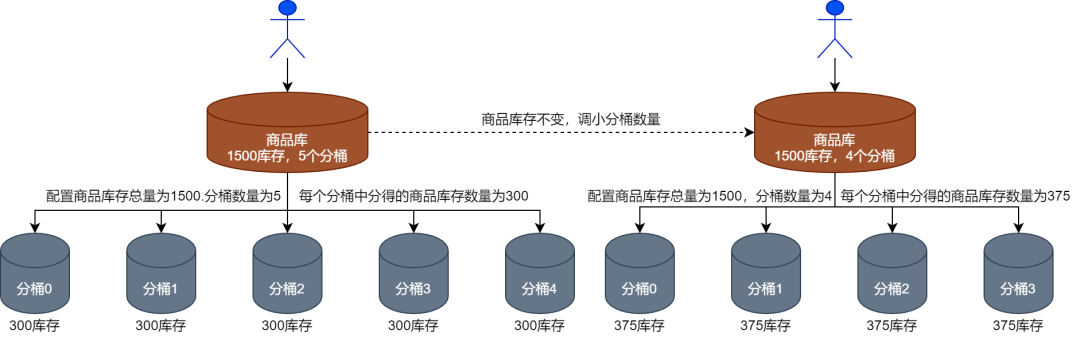
(1) Первая ситуация — корректировка запасов продукции, но количество ковшей остается неизменным, как показано на рисунке ниже.
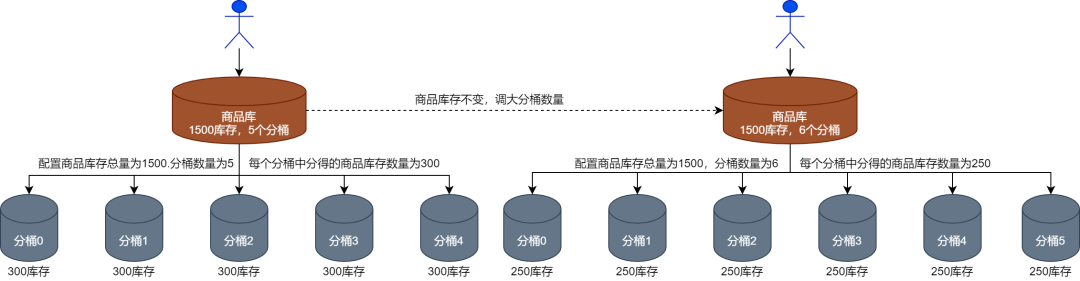
(2) Вторая ситуация заключается в том, что товарные запасы остаются неизменными, а количество ведра увеличивается или уменьшается, как показано на рисунке ниже.
(3) Третья ситуация — корректировка как запаса продукции, так и количества ведра, как показано на рисунке ниже.
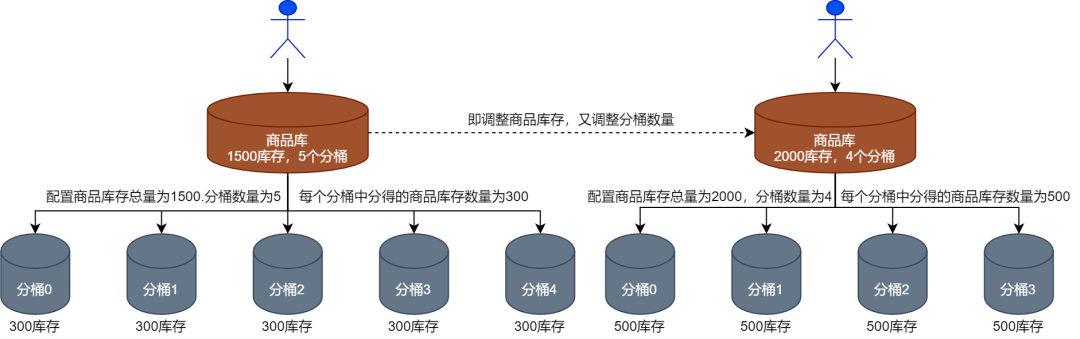
Фактически, эти три ситуации при внедрении системы срочных продаж представляют собой, по сути, корректировку запасов продукции и количества корзин. Система срочных продаж должна поддерживать операции по корректировке этих стратегий в реальном времени.
8. Резюме
В этой главе запасы товаров в основном делятся на склады, столы и ведра. Сначала кратко описываются требования этой главы. Впоследствии разрабатываются цели оптимизации запасов. Затем были разработаны и объяснены подтаблицы и корзины инвентаризации.
Затем были разработаны данные кэша, включенные в подбазу данных инвентаризации товаров, таблицы и сегменты, а также согласованность между данными кэша и данными базы данных. Наконец, были разработаны данные по сегментированию для сброса и корректировки запасов продуктов.
9. Напишите в конце
В дополнение к высокопроизводительному шлюзу, который в настоящее время обновляется, Glacier's Knowledge Planet также имеет 7 других проектов, таких как рукописные высокопроизводительные универсальные компоненты предохранителей, распределенная система обмена мгновенными сообщениями IM, распределенная система флэш-продаж Sekill, рукописный RPC и простой Подождите, требования, планы, архитектура, реализация и т. д. этих проектов взяты из реальных бизнес-сценариев в Интернете, что позволяет вам по-настоящему изучить планы внедрения бизнеса и технологий крупных интернет-компаний и эффективно преобразовать их в систему. свои собственные резервы знаний.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
