10 статей из RAG-2024Q1
Приближается большая модель, а статью невозможно прочитать.
В области крупномасштабных модельных исследований и инженерных приложений изменения настолько быстры, что было бы несколько консервативно описывать их как «изменения с каждым днем». Даже по технологии RAG с начала 2024 года в академическом сообществе появилось множество высококачественных исследовательских работ. Здесь опытные программисты выбрали десять репрезентативных работ, чтобы предоставить полезные ссылки и вдохновение для каждого исследования и практики.
1. RAG и точная настройка: исследование трубопроводов, компромиссов и пример сельского хозяйства
Название статьи: RAG против тонкой настройки: трубопроводы, компромиссы и практический пример сельского хозяйства Адрес статьи: https://arxiv.org/abs/2401.08406.

В этой статье подробно рассматривается, как разработчики могут использовать RAG и тонкую настройку (FT) для интеграции частных данных и отраслевых данных в большие языковые модели (LLM). В статье подробно объясняется, как применять эти технологии к основным LLM, таким как Llama2-13B, GPT-3.5 и GPT-4, уделяя особое внимание точному извлечению информации, генерации вопросов и ответов, процессу тонкой настройки модели и оценке эффекта. Результаты исследования показывают, что за счет тонкой настройки модель может эффективно использовать междоменную информацию и значительно повысить релевантность ответов. Кроме того, в этой статье подчеркиваются широкий потенциал и явные преимущества LLM для применения во многих областях промышленности.
2. Сравнение тонкой настройки и RAG для необщедоступных знаний
Название статьи: Точная настройка против расширенной генерации менее популярных знаний Адрес статьи: https://arxiv.org/pdf/2403.01432.pdf.
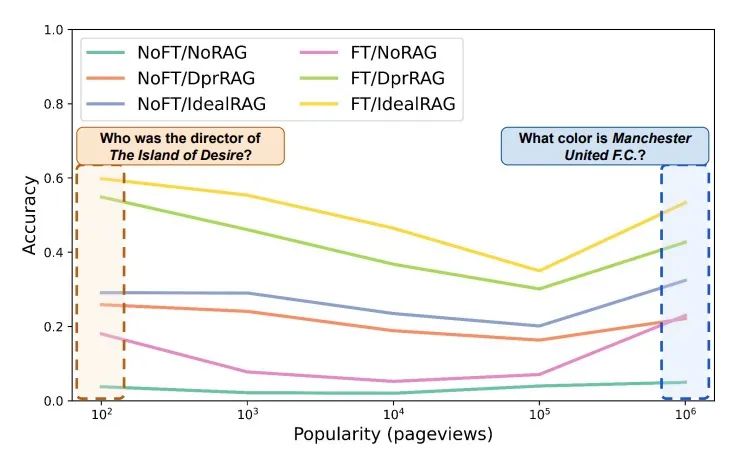
При выполнении задач вопросов и ответов в этой статье проводится углубленный анализ двух методов извлечения взаимосвязей и построения графов (RAG) и тонкой настройки (FT) для повышения способности больших языковых моделей (LLM) обрабатывать простые задачи. проблемы с частотным объектом. Результаты исследования показывают, что, хотя методы тонкой настройки позволяют добиться значительного повышения производительности при распознавании объектов разного уровня популярности, RAG превосходит другие методы сравнения с точки зрения производительности. Кроме того, благодаря постоянному развитию технологий поиска и улучшения данных, возможности методов RAG и FT в настройке LLM для работы с низкочастотными объектами были значительно расширены.
3. Улучшите языковые модели, извлекая из триллионов токенов
Название статьи: Улучшение языковых моделей путем извлечения из триллионов токенов Адрес статьи: https://arxiv.org/abs/2112.04426.
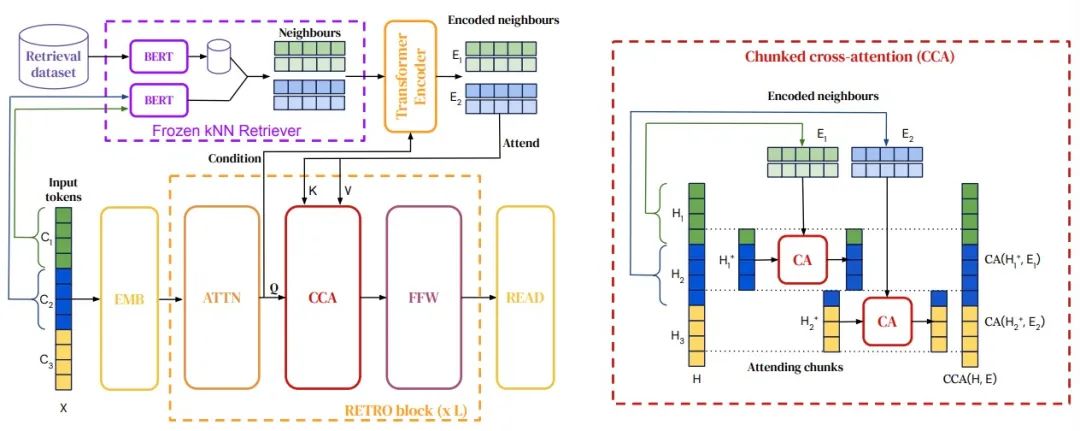
В этом исследовании предлагается инновационный преобразователь RAG, который повышает производительность авторегрессионных языковых моделей за счет условной обработки отрывков текста, полученных из огромного корпуса. Хотя этот Трансформер использует значительно меньше параметров, чем существующие модели, такие как GPT-3, после тонкой настройки он хорошо справляется с такими задачами, как ответы на вопросы. Это достигается за счет объединения фиксированного ретривера Берта, дифференцируемых кодеров и механизмов перекрестного внимания блоков, что позволяет на этапе прогнозирования использовать на порядок больше данных, чем раньше. Этот метод открывает новый путь использования явной памяти для масштабного улучшения возможностей LLM.
4. Адаптируйте языковые модели к RAG, специфичным для конкретной предметной области.
Название статьи: RAFT: адаптация языковой модели к RAG, специфичному для предметной области Адрес статьи: https://arxiv.org/abs/2403.10131.
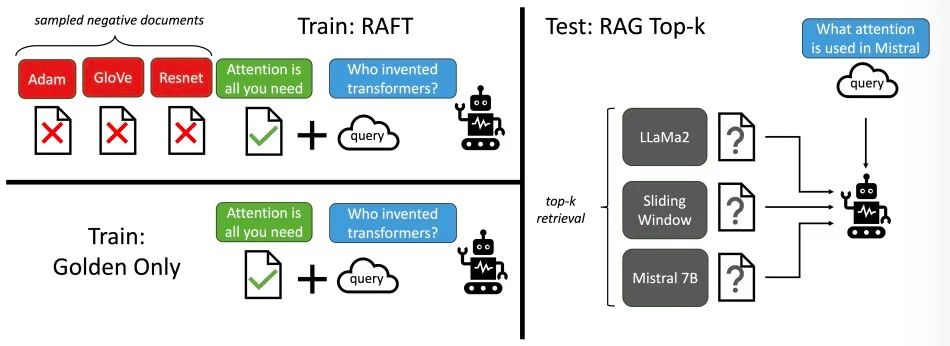
RAFT (Retrival Augmented FineTuning) — это инновационный метод обучения, предназначенный для улучшения способности предварительно обученных моделей большого языка (LLM) отвечать на вопросы в конкретных областях. RAFT фокусируется на тонкой настройке модели, чтобы она научилась игнорировать ненужные полученные документы в процессе вопросов и ответов, тем самым гибко усваивая новые знания. Целенаправленно интегрируя соответствующую информацию в полученные документы, RAFT значительно повышает эффективность вывода модели и общую производительность на нескольких наборах данных, включая PubMed, HotpotQA и Gorilla.
5. Модифицируемая ТРЯПКА
Название статьи: Дополненная генерация корректирующего поиска Адрес статьи: https://arxiv.org/abs/2401.15884.
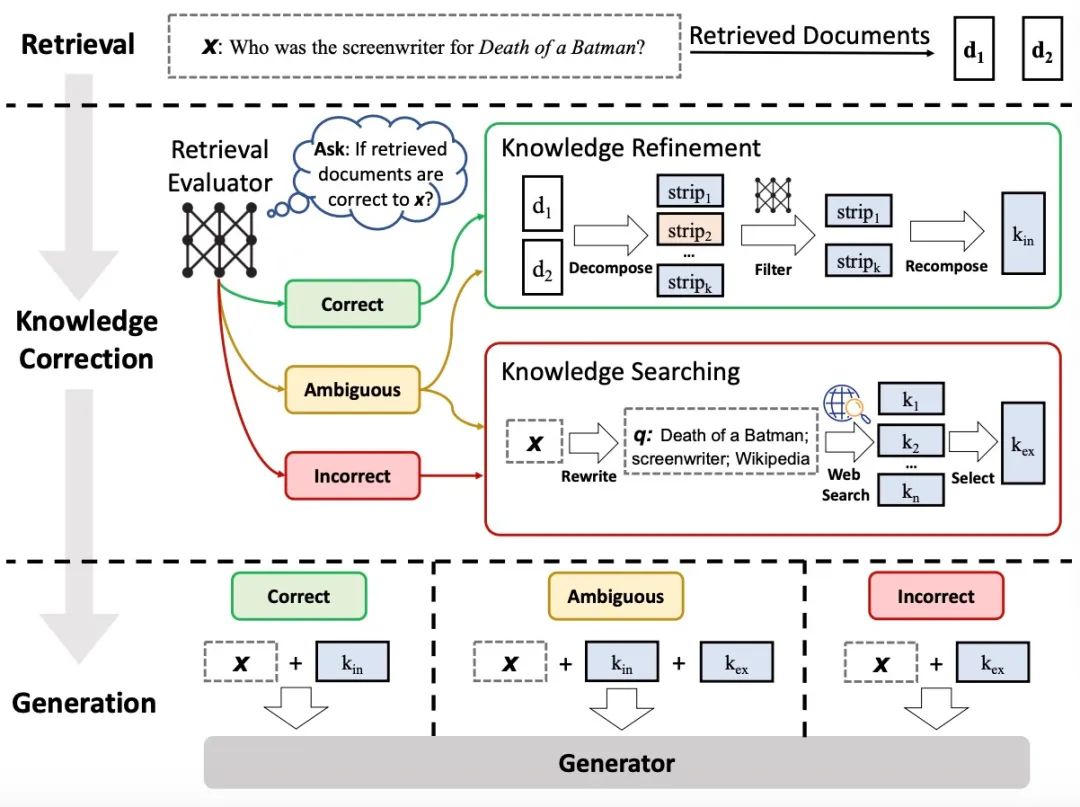
В рамках RAG это исследование представляет новую стратегию, направленную на значительное повышение надежности и точности больших языковых моделей. Чтобы устранить подводные камни, которые могут возникнуть при использовании релевантности поискового документа, используется оценщик поиска для количественной оценки качества и релевантности документов, возвращаемых по заданному запросу, тем самым реализуя основанный на доверии адаптивный механизм поиска. Чтобы преодолеть ограничения статических баз данных, этот метод объединяет крупномасштабные ресурсы сетевого поиска, чтобы предоставить более богатый набор документов для модели. Кроме того, ее оригинальный алгоритм декомпозиции и реорганизации гарантирует, что модель может сосредоточиться на сборе ключевой информации и отфильтровывать ненужную информацию, тем самым значительно улучшая качество генерации контента. Будучи универсальным автоматическим решением, этот метод значительно расширяет возможности обработки моделей на основе RAG в различных задачах генерации и подтверждается значительным улучшением производительности на четырех различных наборах данных.
6. Получите ответы и понимание от RAG посредством повторяющейся самообратной связи.
Название статьи: RA-ISF: Обучение ответам и пониманию посредством расширения поиска посредством итеративной самообратной связи Адрес статьи: https://arxiv.org/abs/2403.06840.
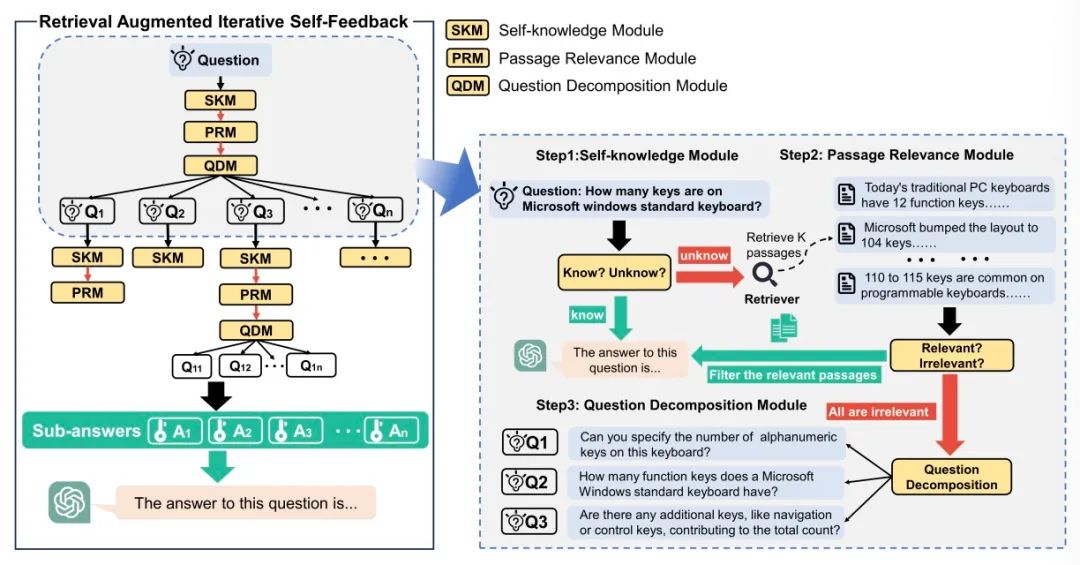
RA-ISF использует итеративный метод RAG с самообратной связью, чтобы значительно повысить эффективность решения проблем больших языковых моделей (LLM) за счет декомпозиции задач и их последовательной обработки в трех специализированных подмодулях. Результаты экспериментов доказывают, что по сравнению с существующими эталонными моделями, включая GPT3.5 и Llama2, RA-ISF демонстрирует превосходные преимущества в производительности. Он добился значительных улучшений в рассуждениях на основе фактов и эффективно уменьшил возникновение галлюцинаций.
7. Контекстно-зависимые рассуждения, вызванные RAG при долгосрочной генерации
Название статьи: RAT: поиск дополненных мыслей вызывает контекстно-зависимое мышление при генерации долгосрочных планов Адрес статьи: https://arxiv.org/abs/2403.05313
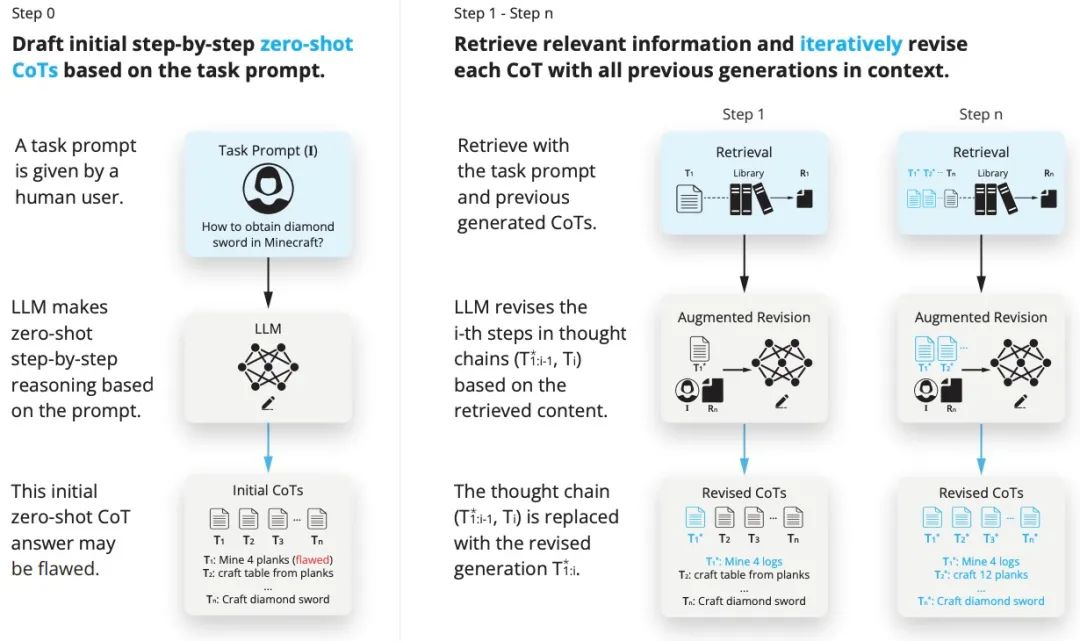
Этот метод значительно расширяет возможности LLM по рассуждению и созданию контента при решении задач долгосрочных зависимостей за счет итеративного уточнения мыслительных цепочек в процессе поиска информации. После интеграции технологии RAG в усовершенствованные модели, такие как GPT-3.5, GPT-4 и CodeLLaMA-7b, ее производительность при выполнении задач в различных областях была значительно улучшена. В частности, с точки зрения написания кода, математических логических рассуждений, творческого письма и планирования конкретных задач средний балл модели увеличился на 13,63%, 16,96%, 19,2% и 42,78% соответственно, демонстрируя ее превосходный эффект оптимизации производительности.
8. Адаптивная RAG для подавления галлюцинаций в больших языковых моделях.
Название статьи: Извлекайте только тогда, когда это необходимо: адаптивное расширение поиска для смягчения галлюцинаций в больших языковых моделях Адрес статьи: https://arxiv.org/abs/2402.10612.
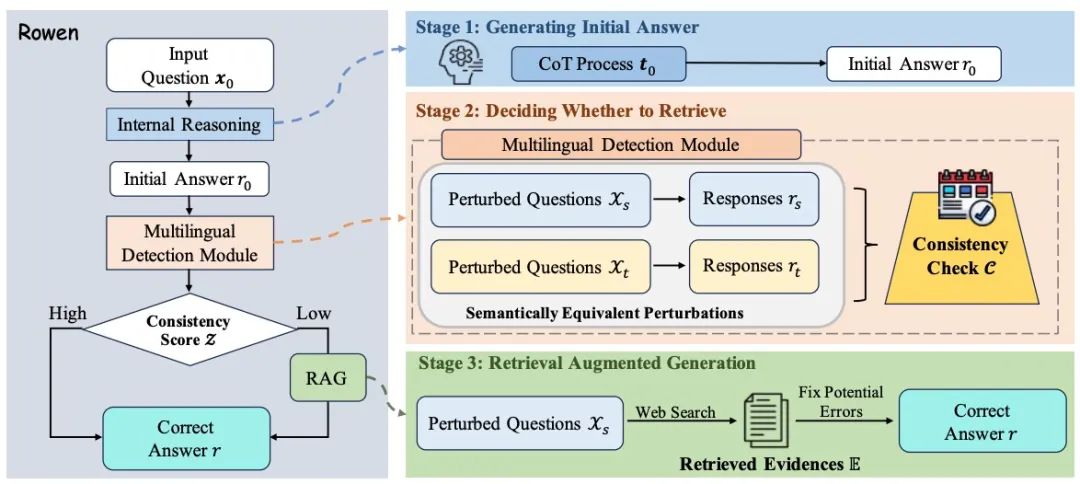
Для LLM феномен галлюцинаций представляет собой серьезную проблему, главным образом из-за ограниченности ее внутренних знаний. Хотя объединение внешней информации может в некоторой степени облегчить эту проблему, оно также может привести к появлению беспорядочных деталей, не имеющих отношения к контексту, вызывая так называемые внешние галлюцинации. Расширенный LLM за счет выборочного использования результатов поиска может выявить основное содержание галлюцинаций при выявлении несоответствий между контекстами. Этот механизм семантического восприятия соответствующим образом взвешивает внутренние логические рассуждения и внешние фактические данные, эффективно снижая вероятность галлюцинаций. Эмпирический анализ подтверждает, что по сравнению с другими современными методами эта стратегия демонстрирует значительные преимущества в обнаружении и уменьшении компонентов галлюцинаций в выходных данных LLM.
9. Рекурсивная абстрактная обработка древовидного поиска.
Название статьи: RAPTOR: Рекурсивная абстрактная обработка для древовидного поиска Адрес статьи: https://arxiv.org/abs/2401.18059.
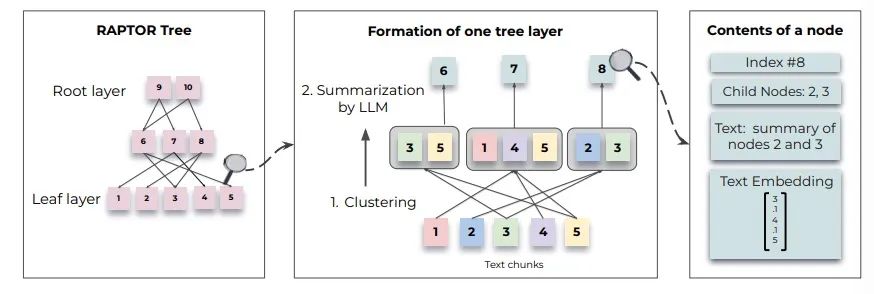
Предлагается инновационный метод языкового моделирования с расширенными поисковыми возможностями, который напрямую уточняет информацию слой за слоем из огромных документов путем построения иерархического сводного дерева. Этот метод отличается от традиционного извлечения отрывков. Он использует рекурсивный процесс для встраивания, группировки и обобщения текстового контента на нескольких уровнях. Этот иерархический метод обработки позволяет нам глубоко анализировать и интегрировать информацию в документе, значительно расширяя возможности обработки сложных запросов, особенно тех задач, которые требуют многоэтапного рассуждения. Обширное сравнительное тестирование показывает, что этот подход может произвести революцию в том, как модели получают доступ к большим базам знаний и используют их, устанавливая новую парадигму для таких областей, как вопросно-ответные системы.
10. Единая RAG из нескольких источников для персонализированной диалоговой системы.
Название статьи: UniMS-RAG: унифицированное поколение с расширенным поиском из нескольких источников для персонализированных диалоговых систем Адрес статьи: https://arxiv.org/abs/2401.13256.
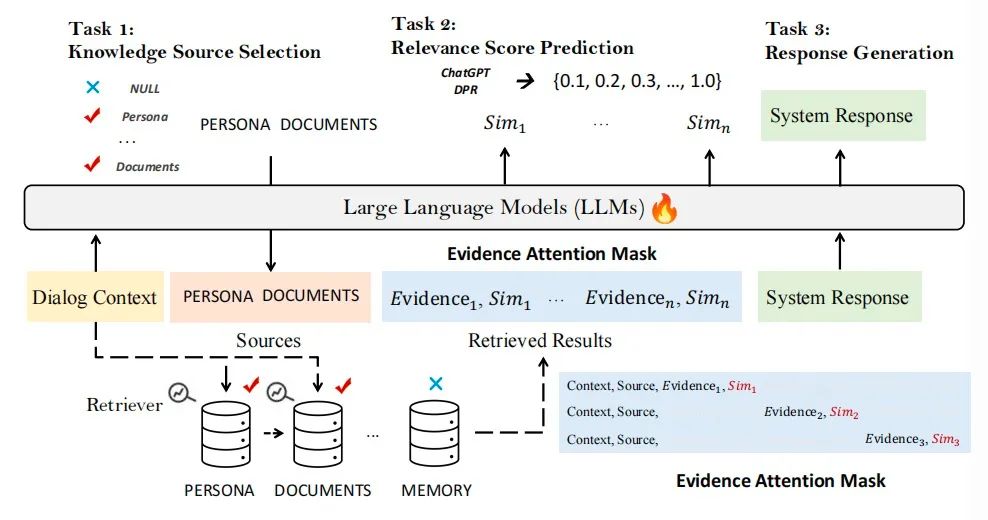
В этой статье разрабатывается новая структура, которая конкретно решает проблемы персонализации в диалоговых системах путем интеграции нескольких источников знаний. Структура разделяет задачу на три ключевые подзадачи: выбор источника знаний, извлечение знаний и построение ответов, и объединяет эти три шага в последовательную парадигму последовательного обучения на этапе обучения. Такая конструкция позволяет модели использовать определенные токены для динамического извлечения и оценки соответствующей информации, тем самым способствуя эффективному взаимодействию с многочисленными источниками знаний. Кроме того, мы вводим детальный механизм самонастройки, который итеративно оптимизирует сгенерированные ответы для улучшения их качества на основе оценок последовательности и релевантности.
Краткое содержание одним предложением
Если вы хотите иметь относительно полное представление о текущей ситуации с RAG, статья «Поиск дополненной информации» Generation for Large Language Models: A Survey》(https://arxiv.org/abs/2312.10997)Возможно, хороший выбор,Если вам нужно более простое объяснение,Вы можете обратиться к старому коду фермера《Большая модельная серия – интерпретация RAG》。



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
