10 ключевых факторов масштабируемости программной системы
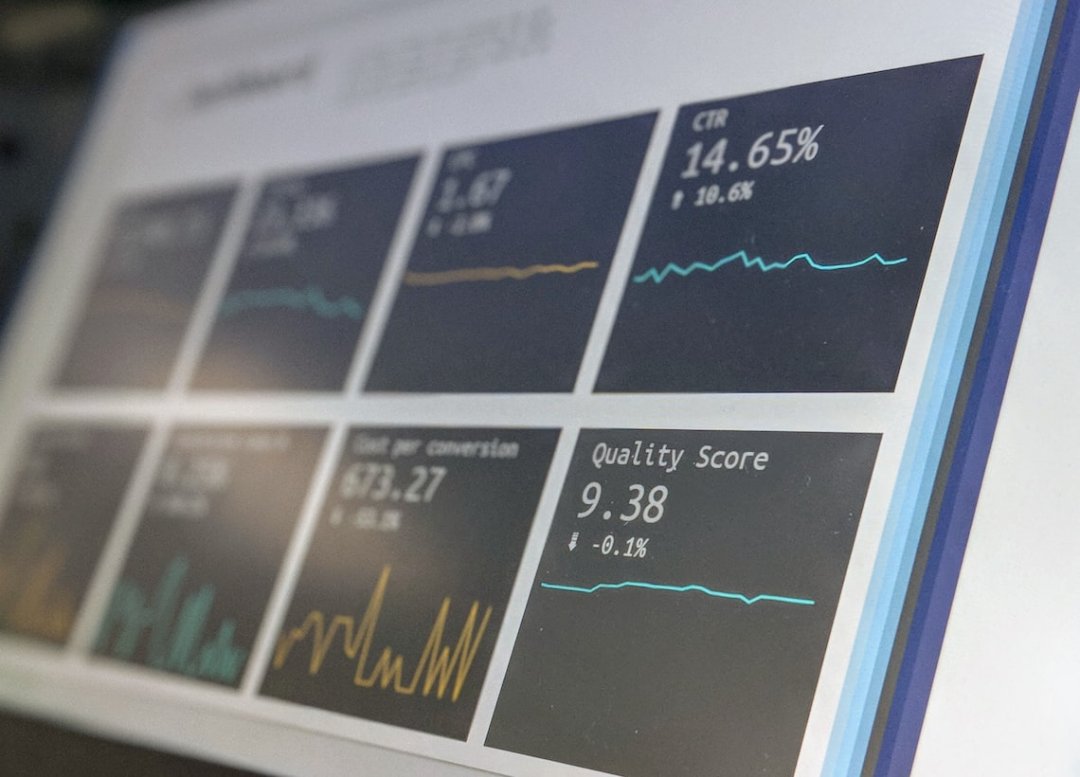
В рамках принципов надежного проектирования программного обеспечения в этой статье основное внимание будет уделено масштабируемости — одному из наиболее важных элементов в создании надежных, ориентированных на будущее приложений.
В современном мире постоянно растущего количества данных и пользователей программное обеспечение должно быть подготовлено к более высоким нагрузкам. Игнорирование масштабируемости похоже на строительство красивого дома на слабом фундаменте: поначалу он может выглядеть великолепно, но в конечном итоге рухнет под давлением.
Независимо от того, создаете ли вы корпоративную систему, мобильное приложение или даже что-то для личного использования, как вы можете гарантировать, что ваше программное обеспечение сможет плавно расти? Масштабируемые системы обеспечивают отличный пользовательский опыт даже во время пиков трафика и высокой загрузки. Приложение, которое не масштабируется, может в лучшем случае разочаровывать, а в худшем — может стать непригодным для использования или полностью выйти из строя при увеличении нагрузки.
В этой статье мы рассмотрим 10 ключевых областей разработки высокомасштабируемой архитектуры. Освоив эти концепции, вы сможете разрабатывать программное обеспечение, которое можно будет развертывать в большом масштабе без дорогостоящей доработки. Ваши пользователи будут благодарны вам за создание приложения, которое сделает их счастливыми сегодня и завтра (когда ваша база пользователей вырастет в 10 раз).
Горизонтальное и вертикальное масштабирование
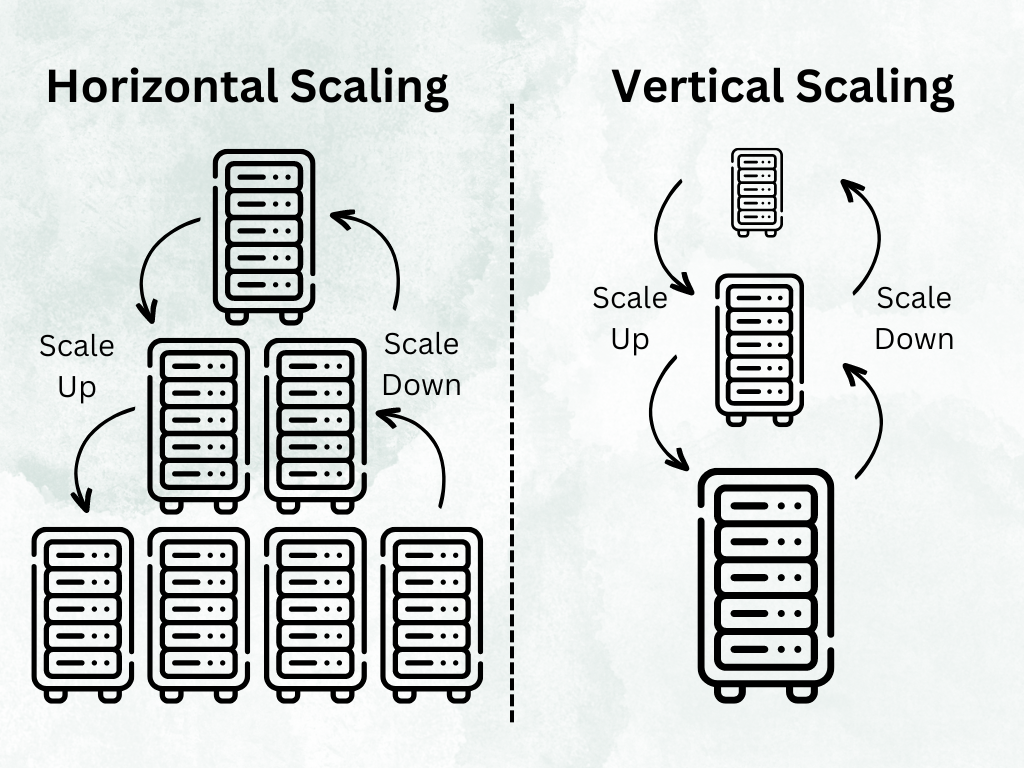
Горизонтальный зум с вертикальным зум
Одной из первых ключевых концепций масштабируемости является понимание разницы между горизонтальным и вертикальным масштабированием. Горизонтальное масштабирование означает увеличение мощности за счет добавления в систему большего количества машин или узлов. Например, добавление дополнительных серверов для поддержки возросшего трафика приложения.
Вертикальное масштабирование предполагает расширение возможностей существующих узлов, например обновление до серверов с более быстрыми процессорами, большим объемом оперативной памяти или увеличенной емкостью хранилища.
Вообще говоря, горизонтальное масштабирование предпочтительнее, поскольку оно обеспечивает более высокую надежность за счет избыточности. Если один узел выходит из строя, другие узлы могут взять на себя рабочую нагрузку. Горизонтальное масштабирование также обеспечивает большую гибкость и может постепенно расширяться по мере необходимости. При вертикальном масштабировании вам необходимо полностью обновить оборудование, чтобы справиться с возросшей нагрузкой.
Однако вертикальное масштабирование может быть полезно, когда конкретные задачи, такие как обработка данных с интенсивным использованием ЦП, требуют увеличения вычислительной мощности. В целом масштабируемая архитектура использует комбинацию методов вертикального и горизонтального масштабирования для корректировки требований к системным ресурсам с течением времени.
балансировка нагрузки
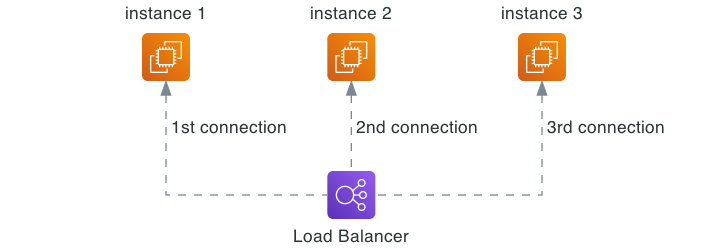
После горизонтального масштабирования путем добавления серверов вам понадобится способ равномерно распределять запросы и трафик между этими узлами. Здесь на помощь приходит балансировка нагрузки. Балансировщик нагрузки находится перед сервером и эффективно направляет входящие запросы на сервер.
Это предотвращает перегрузку любого отдельного сервера. балансировка нагрузка реализует различные алгоритмы, такие как опрос, наименьшее количество соединений или IP Хэш, чтобы определить, как распределить нагрузку. Более продвинутая балансировка Сервер может обнаруживать состояние работоспособности и адаптивно перенаправлять трафик от вышедших из строя узлов.
балансировка нагрузка максимизирует использование ресурсов и повышает производительность. Это также обеспечивает высокую доступность и надежность. Если сервер выходит из строя, балансировка Сервер нагрузки перенаправит трафик на оставшийся онлайн-сервер. Эта избыточность позволяет вашей системе адаптироваться к сбою одного сервера.
Внедрение балансировки нагрузки вместе с автомасштабированием позволяет вашей системе плавно и легко масштабироваться. Ваше приложение может легко обрабатывать большие изменения трафика, не сталкиваясь с проблемами емкости.
Расширение базы данных
По мере роста использования приложений база данных, поддерживающая систему, может стать узким местом. Существует несколько методов масштабирования базы данных для удовлетворения высоких нагрузок чтения/записи. Однако базы данных являются одним из наиболее сложных для масштабирования компонентов в большинстве систем.
Выбор базы данных
Выбор правильной базы данных имеет решающее значение для эффективного масштабирования вашей системы баз данных. Это зависит от множества факторов, включая тип хранимых данных и ожидаемые шаблоны запросов. Различные типы данных (например, данные метрик, журналы, корпоративные данные, графические данные и хранилища ключей/значений) имеют разные характеристики и требования, которые требуют индивидуальных решений для баз данных.
Для данных метрик высокая пропускная способность записи имеет решающее значение для записи данных временных рядов, а базы данных временных рядов, такие как InfluxDB или Prometheus, могут быть более подходящими из-за их оптимизированных механизмов хранения и запросов. С другой стороны, для обработки больших объемов неструктурированных данных (например, журналов) базы данных NoSQL, такие как Elasticsearch, могут обеспечить эффективные возможности индексации и поиска.
Для корпоративных данных, требующих строгих транзакций ACID (атомарность, согласованность, изоляция, долговечность) и сложных реляционных запросов, правильным выбором может быть традиционная база данных SQL, такая как PostgreSQL или MySQL. Напротив, для сценариев, требующих простых операций чтения и записи, хранилища ключей и значений, такие как Redis или Cassandra, могут обеспечить доступ к данным с малой задержкой.
При выборе базы Прежде чем передавать данные, необходимо тщательно оценить конкретные требования приложения и его характеристики данных. Иногда, база Комбинация данных (многоязычная персистентность), вероятно, является наиболее эффективной стратегией, объединяющей различные базы в зависимости от их сильных сторон. данные используются в разных частях приложения. В конечном итоге правильный Выбор базы Данные могут существенно повлиять на масштабируемость, производительность и общий успех системы.
вертикальный зум
Простое вложение большего количества ресурсов (таких как ЦП, память и хранилище) на один сервер базы данных может временно снизить возросшую нагрузку. Прежде чем углубляться в сложные концепции расширения базы данных, вам следует сначала попробовать их. Кроме того, вертикальное масштабирование упрощает стек вашей базы данных.
Однако существует физический верхний предел масштабируемости одного сервера. Кроме того, одна база данных остается единой точкой отказа: если расширенный сервер выходит из строя, доступ к данным также прекращается.
Вот почему в дополнение к вертикальному расширению оборудования серверов баз данных крайне важно также использовать технологию горизонтального расширения.
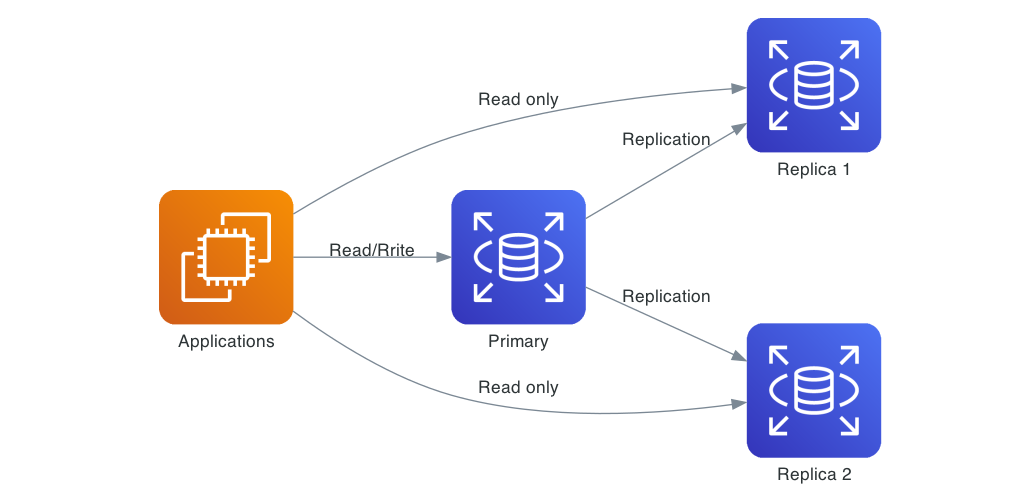
копировать
копировать прохождение между несколькими копированными экземплярами базы данных, чтобы обеспечить избыточность и повысить производительность. Записи в ведущий узел будут направлены в реплику чтения. Чтения могут обслуживаться из реплик.,Тем самым снижая нагрузку на основной сервер. также,копировать Может охватывать избыточностьсерверкопироватьданные,Это исключает риск возникновения единых точек отказа.
Шардинг
Шардинг делит данные базы на несколько меньших серверов, позволяя плавно добавлять больше узлов по мере необходимости.
Шардингили Разделение предполагает деление по определенным критериям.(Напримерклиент ID или географический регион) разделите базу данных на несколько баз данных меньшего размера. Это позволяет масштабировать горизонтально, добавляя больше серверов баз данных.
Кроме того, вам следует сосредоточиться на других областях, которые могут помочь расширить вашу базу данных:
- Архитектурная денормализация включает в себя базу данныхвданныеповторить,уменьшить необходимость в сложных соединениях в запросах,Это повышает производительность запросов.
- Размещение часто используемых элементов в быстрой кэш-памяти может уменьшить количество часто используемых элементов. данныезапрос. попаданий в кэш можно избежать с более медленной базы данных Залезайданные。
Асинхронная обработка
Синхронные циклы запроса-ответа могут создавать узкие места, препятствующие масштабируемости, особенно для длительных или IO Интенсивные задачи. Асинхронная Очереди обработки работают в фоновом режиме, немедленно освобождая ресурсы для использования другими запросами.
Например, отправка задания на перекодирование видео может напрямую заблокировать Web запросы, тем самым негативно влияя на пользовательский опыт. Вместо этого задачу перекодирования можно поставить в очередь и Асинхронная обработка. Пользователи получают немедленные ответы, а задачи перекодирования решаются отдельно.
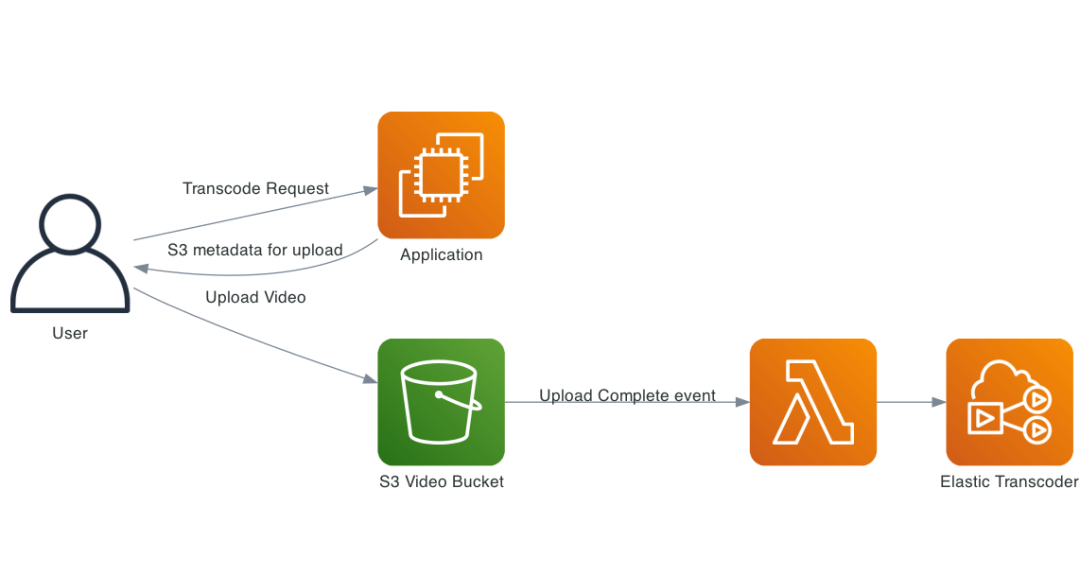
Пример асинхронной загрузки и перекодирования видео
Асинхронные задачи могут выполняться одновременно фоновыми работниками, которые горизонтально масштабируются на нескольких серверах. Размер очереди можно отслеживать, чтобы динамически добавлять больше работников. Нагрузка распределяется равномерно, что позволяет избежать перегрузки отдельного работника.
Перенос рабочих нагрузок с синхронного на асинхронный позволяет приложениям плавно обрабатывать пики трафика, не зависая. Система остается отзывчивой под нагрузкой благодаря мощной асинхронной обработке на основе очередей.
система без гражданства
По сравнению с государственным дизайном, система без гражданства легче масштабировать по горизонтали. Когда состояние приложения сохраняется в базе данные распределены кэшждать на внешнем хранилище вместо локального сервера, новые экземпляры можно запускать по мере необходимости.
Напротив, система с отслеживанием состояния требует закрепленных сеансов или данных копировать между экземплярами. Приложения без сохранения состояния не зависят от конкретного приложения. Запросы могут быть перенаправлены на любой доступный ресурс.
Внешнее сохраненное состояние также обеспечивает лучшую отказоустойчивость. Потеря любого сервера приложений без сохранения состояния не имеет никакого значения, поскольку он не сохраняет важные данные, которые не сохраняются. Другие серверы могут легко взять на себя обработку.
Архитектура без сохранения состояния повышает надежность и масштабируемость. Ресурсы можно гибко расширять,сохраняя при этом развязку от отдельных экземпляров. Однако,Добавлено внешнее хранилище состояний кэшилибаза Стоимость запроса данных. Эти компромиссы необходимо тщательно оценивать при разработке веб-приложений.
кэш
Кэшчасто используемые данные в быстрой памяти — мощный метод оптимизации масштабируемости. обрабатывать запросы на чтение из кэша с низкой задержкой, можно существенно сократить бэкенд базу Загрузка данных и повышение производительности.
Например, для кэша отлично подойдет информация каталога товаров, которая редко меняется. Последующие запросы страниц продукта могут быть сделаны из Redis или Memcached. Получите данные, чтобы избежать перегрузки хранилища MySQL. Стратегия аннулирования кэша помогает поддерживать согласованность данных.
Кэш также полезен для ресурсоемких процессов, таких как рендеринг шаблонов. Вы можете кэшировать вывод и обойти избыточный рендеринг при каждом запросе. Облачное сияние ждать CDN кэшировать глобально и предоставлять изображения, CSS и JS ждать статические ресурсы.
Пример Redis Голанга:
package main
import (
"database/sql"
"encoding/json"
"fmt"
"log"
"net/http"
"time"
"github.com/go-redis/redis"
_ "github.com/go-sql-driver/mysql"
)
const (
dbUser = "your_mysql_username"
dbPassword = "your_mysql_password"
dbName = "your_mysql_dbname"
redisAddr = "localhost:6379"
)
type Product struct {
ID int `json:"id"`
Name string `json:"name"`
Price int `json:"price"`
}
var db *sql.DB
var redisClient *redis.Client
func init() {
// Initialize MySQL connection
dbSource := fmt.Sprintf("%s:%s@/%s", dbUser, dbPassword, dbName)
var err error
db, err = sql.Open("mysql", dbSource)
if err != nil {
log.Fatalf("Error opening database: %s", err)
}
// Initialize Redis client
redisClient = redis.NewClient(&redis.Options{
Addr: redisAddr,
Password: "", // No password set
DB: 0, // Use default DB
})
// Test the Redis connection
_, err = redisClient.Ping().Result()
if err != nil {
log.Fatalf("Error connecting to Redis: %s", err)
}
log.Println("Connected to MySQL and Redis")
}
func getProductFromMySQL(id int) (*Product, error) {
query := "SELECT id, name, price FROM products WHERE id = ?"
row := db.QueryRow(query, id)
var product Product
err := row.Scan(&product.ID, &product.Name, &product.Price)
if err != nil {
return nil, err
}
return &product, nil
}
func getProductFromCache(id int) (*Product, error) {
productJSON, err := redisClient.Get(fmt.Sprintf("product:%d", id)).Result()
if err == redis.Nil {
// Cache miss
return nil, nil
} else if err != nil {
return nil, err
}
var product Product
err = json.Unmarshal([]byte(productJSON), &product)
if err != nil {
return nil, err
}
return &product, nil
}
func cacheProduct(product *Product) error {
productJSON, err := json.Marshal(product)
if err != nil {
return err
}
key := fmt.Sprintf("product:%d", product.ID)
return redisClient.Set(key, productJSON, 10*time.Minute).Err()
}
func getProductHandler(w http.ResponseWriter, r *http.Request) {
productID := 1 // For simplicity, we are assuming product ID 1 here. You can pass it as a query parameter.
// Try getting the product from the cache first
cachedProduct, err := getProductFromCache(productID)
if err != nil {
http.Error(w, "Failed to retrieve product from cache", http.StatusInternalServerError)
return
}
if cachedProduct == nil {
// Cache miss, get the product from MySQL
product, err := getProductFromMySQL(productID)
if err != nil {
http.Error(w, "Failed to retrieve product from database", http.StatusInternalServerError)
return
}
if product == nil {
http.Error(w, "Product not found", http.StatusNotFound)
return
}
// Cache the product for future requests
err = cacheProduct(product)
if err != nil {
log.Printf("Failed to cache product: %s", err)
}
// Respond with the product details
json.NewEncoder(w).Encode(product)
} else {
// Cache hit, respond with the cached product details
json.NewEncoder(w).Encode(cachedProduct)
}
}
func main() {
http.HandleFunc("/product", getProductHandler)
log.Fatal(http.ListenAndServe(":8080", nil))
}
Стратегическое использование кэша может снизить нагрузку на вашу инфраструктуру и обеспечить масштабирование по мере добавления большего количества кэш-серверов. кэш лучше всего подходит для рабочих нагрузок с интенсивным чтением и повторяющимися шаблонами доступа. это и база данных Шардинги Асинхронная Совместная обработка обеспечивает выигрыш в масштабируемости.
Оптимизация пропускной способности сети
Для распределенных архитектур, распределенных по нескольким регионам,Оптимизация использования пропускной способности сети является ключом к масштабируемости. Сетевые вызовы могут стать узким местом,Установите ограничения на пропускную способность и задержку.
сжатиеикэшждать Технология оптимизации пропускной способности уменьшает количество сетевых переходовипереданныйданныеколичество。сжатие API ибаза Скорость реагирования данных минимизирует требования к пропускной способности.
проходить HTTP/2 Постоянные соединения позволяют отправлять несколько запросов по открытому каналу. Это снижает накладные расходы, улучшает использование ресурсов и позволяет избежать HTTP Блокировка начала линии. Однако HTTP/2 все еще подлежит TCP Проблема с блокировкой заголовка. Так что теперь мы можем даже использовать QUIC завершенный HTTP/3 вместо этого TCP и TLS, и это позволяет избежать TCP Блокировка начала линии.
CDN распределяет ресурсы в периферийных местоположениях, чтобы приблизить данные к пользователям. Это доставляет контент из близлежащих мест, что снижает стоимость передачи дорогостоящих междугородных линий связи.
Пример языка Gzip Go:
package main
import (
"github.com/labstack/echo/v4"
"github.com/labstack/echo/v4/middleware"
)
func main() {
e := echo.New()
// Middleware
e.Use(middleware.Logger())
e.Use(middleware.Recover())
e.Use(middleware.Gzip()) // Add gzip compression middleware
// Routes
e.GET("/", helloHandler)
// Start server
e.Logger.Fatal(e.Start(":8080"))
}
func helloHandler(c echo.Context) error {
return c.String(200, "Hello, Echo!")
}
общий,Расширение требует целостного взгляда,Включает не только вычисления и хранение,Также включает подключение к Интернету. провести минимизацию прыжков, сжатие, Кэширование для оптимизации использования полосы пропускания очень ценно для построения больших систем с высокой пропускной способностью и низкой задержкой.
прогрессивное улучшение
прогрессивное улучшение – это способ помочь улучшить Web Стратегии масштабируемости приложений. Идея состоит в том, чтобы сначала создать базовую функциональность, а затем постепенно улучшать возможности браузера и устройства.
Например, вы можете разработать базовый HTML/CSS веб-сайт, чтобы обеспечить его доступность в любом браузере. Затем вы можете добавить расширенные CSS и JavaScript будет постепенно улучшаться с JS Взаимодействие поддерживается современными браузерами.
Предоставление базового HTML в первую очередь обеспечивает быстрое «время взаимодействия» и работает на всех платформах. Затем загружаются улучшения для оптимизации работы без блокировки. Такой сбалансированный подход расширяет охват и одновременно использует возможности. Qwik, например, включает эту концепцию в основу своей структуры.
Постепенное улучшение также способствует масштабируемости. Простые страницы требуют меньше ресурсов и лучше масштабируются. При необходимости вы можете добавить более продвинутую функциональность, а не заморачиваться заранее для каждого возможного варианта использования.
В целом, прогрессивное улучшение позволяет веб-приложению эффективно расширяться от базовой функциональности до расширенной функциональности в зависимости от возможностей устройства и потребностей пользователя.
Грамотный переход на более раннюю версию
ипрогрессивное улучшение Напротив,Грамотный переход на более раннюю версию предполагает начало работы с опытом высокого уровня.,и сокращать функциональность при обнаружении ограничений. Это позволяет приложениям плавно масштабироваться при ограниченности ресурсов.
Например,Приложения с богатой графикой могут обнаруживать мобильные устройства с низким энергопотреблением,И адаптируйтесь к переходу от продвинутых визуальных эффектов к более простым презентациям. или человек,Серверные части могут регулировать второстепенные операции во время пиковых нагрузок для поддержания основной функциональности.
Даже в неоптимальных условиях,Грамотный переход на более раннюю версию также сохраняет важные рабочие процессы пользователей. Ошибки из-за ограничений пропускной способности, возможностей устройства и пиков трафика сведены к минимуму. Опыт все еще актуален,вместо того, чтобы потерпеть катастрофическое поражение.
Переход на более раннюю версию — ценный инструмент,Его следует включить и спланировать на начальном этапе разработки функций продукта. Возможность автоматически и вручную деактивировать функции необходима для обеспечения правильной работы системы в различных ситуациях.,Напримерсистемаперегрузка、Миграция или непредвиденные проблемы с производительностью.
Когда система испытывает высокие нагрузки и перегружена слишком большим трафиком, динамическая деактивация некритических функций может снять нагрузку и предотвратить полный сбой в работе службы. Такое разумное использование деградации функций гарантирует, что основные функции остаются работоспособными, и предотвращает каскадные сбои во всем приложении.
Во время миграции или обновления базы данных,Понижение функций может помочь сохранить стабильность системы. временно отключить некоторые функции,Может снизить сложность процесса миграции,Тем самым сводя к минимуму риск противоречивости или повреждения данных. После завершения и проверки миграции,Эти функции можно легко повторно активировать.
также,В случае обнаружения серьезной ошибки или уязвимости безопасности в определенной функции.,Функциональная деградация может быть полезным механизмом. Своевременное отключение затронутых функций может предотвратить дальнейший ущерб при решении проблемы.,Тем самым обеспечивая целостность всей системы.
общий,Включите деградацию функций в стратегию проектирования и разработки продукта.,Позволяет системе изящно справляться со сложными ситуациями,Повышение устойчивости,и поддерживать бесперебойную работу пользователя в неблагоприятных условиях.
Создание механизмов обнаружения устройств, мониторинга производительности и ограничения может повысить устойчивость приложений при увеличении или уменьшении масштаба. Ресурсы можно динамически корректировать до оптимального уровня на основе ограничений и приоритетов в реальном времени.
Масштабируемость кода
Лучшие практики масштабируемости Инфраструктура и Архитектура. Но хорошо написанный и оптимизированный код также является ключом к масштабированию. Даже в надежной инфраструктуре неоптимальный код может снизить производительность и использование ресурсов.
Плотные циклы, неэффективные алгоритмы и плохой структурный доступ к данным могут привести к проблемам на сервере. Такие архитектуры, как микросервисы, увеличивают параллелизм, но могут также усугубить эту неэффективность.
Анализатор кода помогает выявить «горячие точки» и «узкие места». Рефакторинг кода для лучшего масштабирования и оптимизации Процессор, память и I/O Использование ресурсов. Распределение обработки по потокам также может улучшить использование многоядерных серверов.
Пример немасштабируемого кода (потоков на запрос):
Даже в сильной инфраструктуре неэффективный код может препятствовать масштабируемости. Например, выделение одного потока на запрос плохо масштабируется — при высокой нагрузке на сервере закончатся потоки.
Асинхронное/событийное программирование и неблокируемость I/O ждать Лучший подход обеспечивает более высокую масштабируемость. Node.js Используйте эту модель для эффективной обработки множества одновременных запросов в одном потоке.
виртуальный потокили goroutine Также более масштабируем, чем пулы потоков. Виртуальные потоки являются легкими и управляются средой выполнения. Например Go в goroutine и Python взеленая нить。
По сравнению с ограниченными потоками операционной системы, сотни тысяч goroutine Можно запускать одновременно. автоматически при запуске goroutine Повторное использование в реальных потоках。Это устраняет накладные расходы на время жизни потока.и Ограничения ресурсов пула потоков。
Несмотря на инфраструктуру,Но тщательно построенный код может максимизировать асинхронную обработку, виртуальные потоки и минимизировать накладные расходы.,Это критично для крупномасштабных приложений.
Пример Java виртуального потока для каждой задачи:
import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class VirtualThreadServer {
public static void main(String[] args) {
final int portNumber = 8080;
try {
ServerSocket serverSocket = new ServerSocket(portNumber);
System.out.println("Server started on port " + portNumber);
ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor();
while (true) {
// Wait for a client connection
Socket clientSocket = serverSocket.accept();
System.out.println("Client connected: " + clientSocket.getInetAddress());
// Submit the request handling task to the virtual thread executor
executor.submit(() -> handleRequest(clientSocket));
}
} catch (IOException e) {
e.printStackTrace();
}
}
static void handleRequest(Socket clientSocket) {
try (
BufferedReader in = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()));
PrintWriter out = new PrintWriter(clientSocket.getOutputStream(), true)
) {
// Read the request from the client
String request = in.readLine();
// Process the request (you can add your custom logic here)
String response = "HTTP/1.1 200 OK\r\nContent-Type: text/html\r\n\r\nHello, this is a virtual thread server!";
// Send the response back to the client
out.println(response);
// Close the connection
clientSocket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
ПРИМЕЧАНИЕ. Если вы хотите запустить приведенный выше код, убедитесь, что у вас есть java 20,будет кодироватькопироватьприезжатьVirtualThreadServer.javaи использовать запустить егоjava --source 20 --enable-preview VirtualThreadServer.java。
Код нуждается в масштабировании точно так же, как инфраструктура. Эффективный код гарантирует оптимальную работу сервера под нагрузкой. Независимо от окружающей архитектуры, перегруженные серверы ухудшают масштабируемость. Оптимизируйте код и масштабируйте инфраструктуру для достижения наилучших результатов.
в заключение
Масштабирование вашего программного обеспечения для удовлетворения роста имеет решающее значение для долгосрочного успеха. Мы изучили горизонтальное масштабирование, балансировку нагрузки, базу данных Шардинг、Асинхронная обработка, кэши оптимизируют ключевые методы ожидания кода для разработки высокомасштабируемой архитектуры.
Хотя масштабирование требует постоянных усилий, инвестиции в масштабируемость на раннем этапе предотвратят болезненные узкие места в будущем. Подумайте о своих потребностях в мощности заранее, а не постфактум. Обеспечьте избыточность, отслеживайте использование, постепенно масштабируйте и распределяйте нагрузку между несколькими узлами.
Благодаря мощному адаптивному дизайну даже при резком росте использования 10 разили 100 раз,Ваше программное обеспечение также может продолжать радовать ваших клиентов. Планирование масштабирования позволит выделить ваше приложение среди множества приложений, которые разрушаются из-за роста. Несмотря на растущий спрос,Но пока ваша платформа остается быстрой, доступной и надежной,Ваши пользователи останутся.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
