10 архитектурных шаблонов для приложений с большими моделями
В процессе формирования новых месторождений мы часто полагаемся на проверенные стратегии, методы и модели. Эта концепция стала обычным явлением для профессионалов в области разработки программного обеспечения, а шаблоны проектирования стали важным навыком для программистов. Однако когда мы переходим к большим модельным приложениям и области искусственного интеллекта, ситуация может быть иной. Перед лицом новых технологий, таких как генеративный искусственный интеллект, нам все еще не хватает зрелых шаблонов проектирования для поддержки этих решений.
Как старый программист, я собрал и обобщил здесь некоторые методы проектирования и архитектурные шаблоны для приложений с большими моделями, пытаясь справиться и решить некоторые проблемы при реализации приложений с большими моделями, такие как проблемы стоимости, проблемы с задержками и генерируемые неточности. ждать.
1. Режим распределения маршрутов
Когда пользователь вводит запрос, он отправляется в центр управления, который играет роль классификации входных данных.
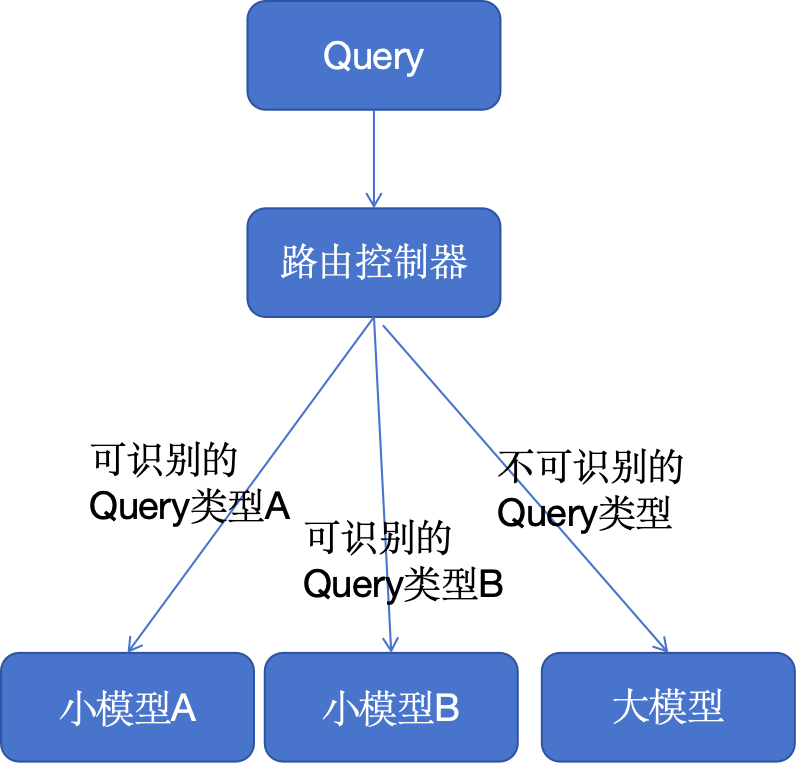
Если запрос можно идентифицировать, он направляется в небольшую языковую модель для обработки, что обычно является более точной, более быстрой и менее затратной операцией. Однако если запрос не может быть распознан, то он будет обработан большой языковой моделью. Хотя запуск больших языковых моделей обходится дороже, они могут успешно возвращать ответы на более широкий спектр запросов. Таким образом, продукты искусственного интеллекта могут достичь баланса между стоимостью, производительностью и пользовательским опытом.
2. Режим прокси для большой модели
Представьте себе экосистему, в которой несколько генеративных моделей ИИ, специализирующихся на конкретных задачах, каждая из которых выступает в качестве эксперта в своей области, работают параллельно и обрабатывают запросы. Этот шаблон мультиплексирования генерирует серию различных ответов, которые затем объединяются в комплексный ответ.
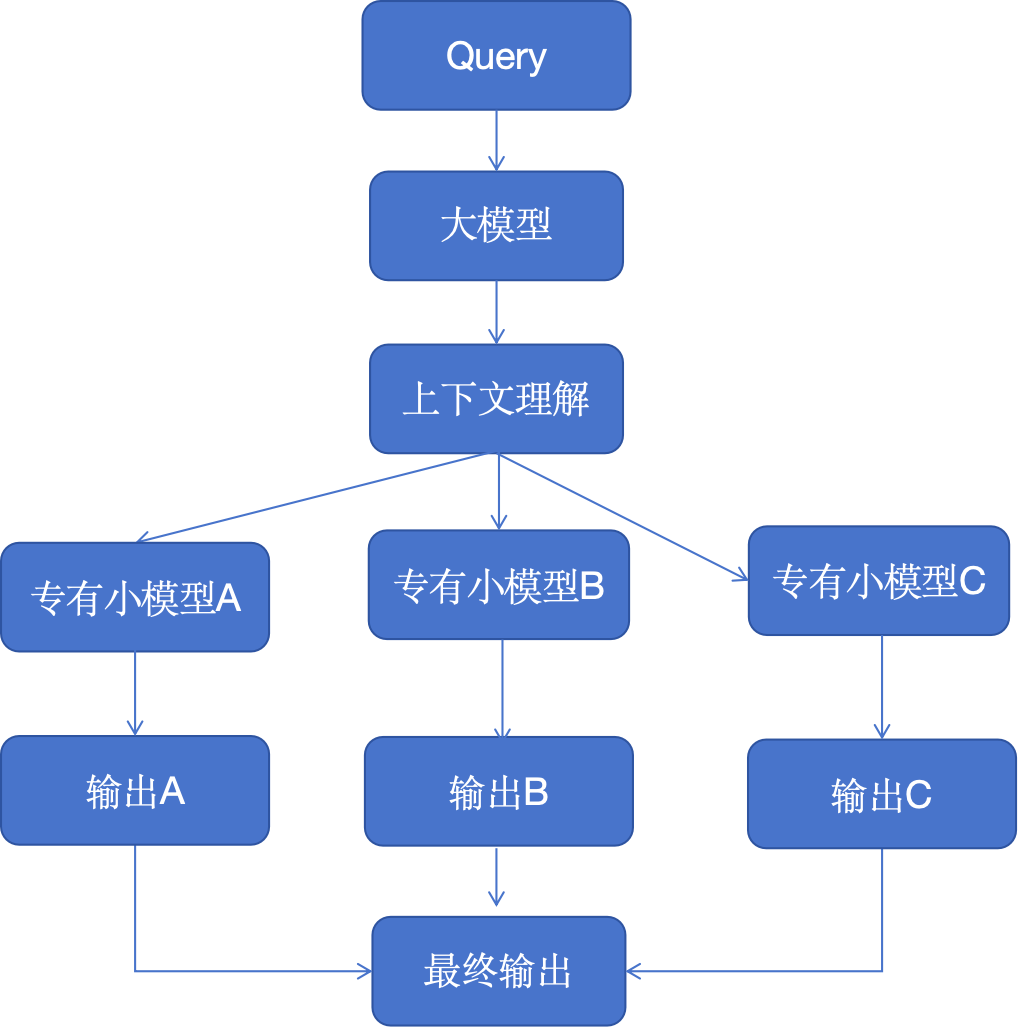
Такая установка идеальна для сложных сценариев решения проблем, где разные аспекты проблемы требуют разного опыта, например, команда экспертов, каждый из которых работает над одним аспектом более крупной проблемы.
Более крупные модели (например, GPT-4) отвечают за понимание контекста и разбиение его на конкретные задачи или информационные запросы, которые передаются более мелким агентам. Эти агенты могут представлять собой меньшие языковые модели, обученные для конкретной задачи, или общие модели с конкретными возможностями, такими как GPT, Llama, контекстные подсказки и вызовы функций.
3. Многозадачный режим тонкой настройки.
В этом архитектурном шаблоне мы настраиваем большую языковую модель для одновременной обработки нескольких задач, а не только одной задачи. Это междоменный метод обучения передаче знаний и навыков, который значительно повышает универсальность модели.
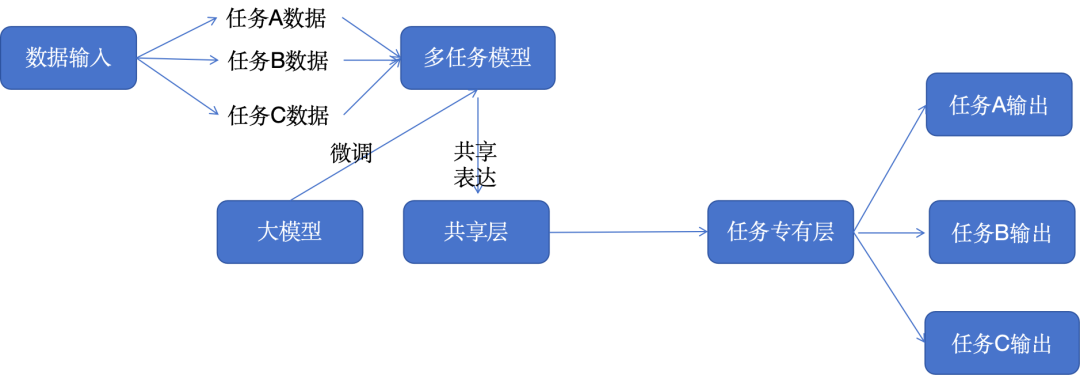
Такой подход к многозадачному обучению особенно полезен для платформ, которым необходимо решать множество сложных задач, таких как виртуальные помощники или исследовательские инструменты на основе искусственного интеллекта. Это значительно упрощает рабочие процессы обучения и тестирования для сложных областей.
При обучении большой языковой модели (LLM) мы можем воспользоваться некоторыми ресурсами и программными пакетами, такими как DeepSpeed и библиотека Transformer Hugging Face.
4. Шаблон стратегии иерархического кэширования для тонкой настройки
Мы внедряем стратегии кэширования и связанные с ними услуги в архитектуры приложений больших моделей, которые могут успешно решать совокупные проблемы стоимости, избыточности данных и данных обучения.
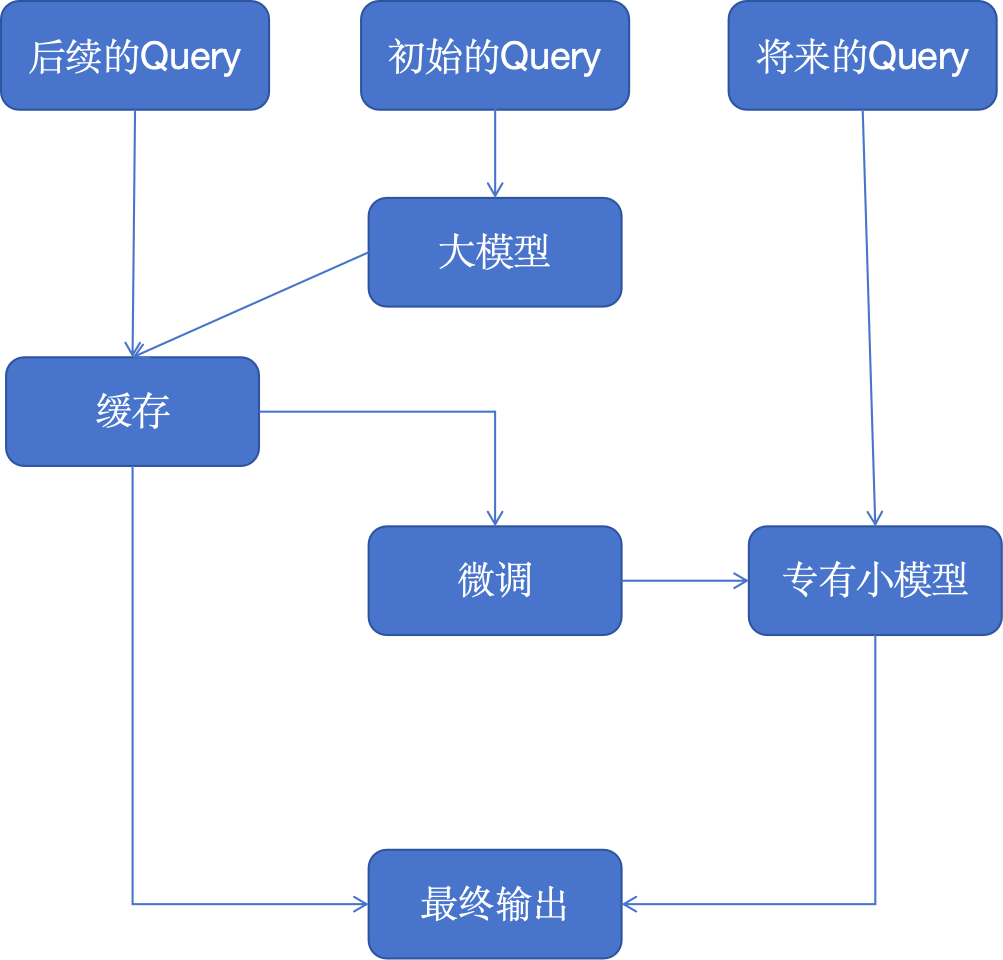
Сохраняя эти первоначальные результаты, система может быстро предоставлять ответы на последующие запросы, что значительно повышает эффективность. Когда мы накопим достаточно данных, будет запущен уровень тонкой настройки, использующий обратную связь от ранних взаимодействий для дальнейшего уточнения более специализированной модели.
Собственные большие модели не только оптимизируют операционные процессы, но и лучше адаптируют знания искусственного интеллекта к конкретным задачам, делая его более эффективным в средах, требующих высокой степени точности и адаптируемости, таких как обслуживание клиентов или создание персонализированного контента.
Пользователи, которые только начинают работу, могут использовать готовые службы, такие как GPTCache, или использовать общие базы данных кэширования, такие как Redis, Cassandra и Memcached, для запуска собственных служб. Добавляя в смесь другие сервисы, всегда не забывайте отслеживать и измерять задержку.
5. Режим смешанных правил
Многие современные бизнес-системы и корпоративные приложения по-прежнему в некоторой степени полагаются на архитектуру, основанную на правилах. Объединив большие модели с логикой, основанной на правилах, мы можем объединить структурированную точность с целью создания творческих и дисциплинированных решений.
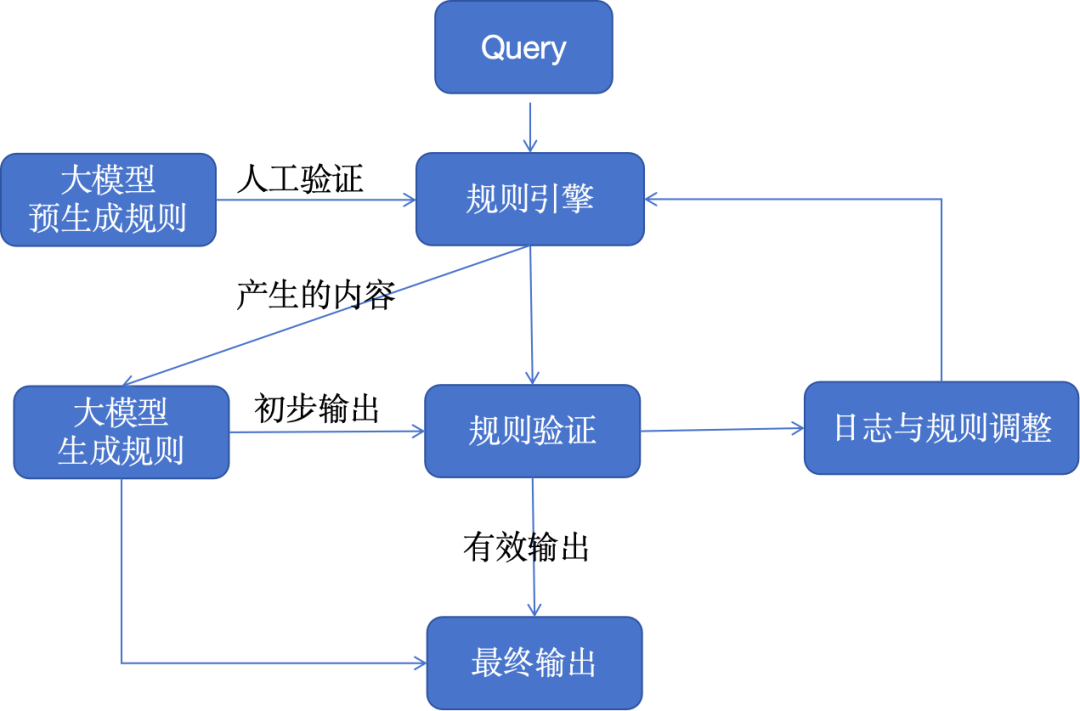
Это очень эффективный архитектурный шаблон для отраслей или продуктов, которые должны строго соответствовать стандартам или правилам, гарантируя, что ИИ останется инновационным, сохраняя при этом установленные идеальные параметры. Например, эту архитектуру можно применять для генерации намерений и потоков сообщений для телефонной системы IVR или традиционного чат-бота, основанного на правилах (не LLM).
6. Модель графа знаний
Сочетание графов знаний с генеративными моделями искусственного интеллекта дает им сверхспособности, ориентированные на факты, делая выходные данные не только контекстуальными, но и более основанными на фактах.

Этот подход имеет решающее значение для приложений, в которых нельзя игнорировать подлинность и точность контента, например, при создании образовательного контента, медицинских консультациях или в любой другой области, где дезинформация может иметь серьезные последствия.
Графы знаний и их онтологии могут разлагать сложные темы или вопросы в структурированные форматы, обеспечивая глубокую контекстуальную основу для больших языковых моделей. Мы даже можем создавать онтологии в таких форматах, как JSON или RDF, с помощью языковых моделей.
Сервисы баз данных графов, которые можно использовать для построения графов знаний, включают ArangoDB, Amazon Neptune, Google Dgraph, Azure Cosmos DB и Neo4j. Кроме того, для доступа к более полному графу знаний можно использовать более широкий спектр наборов данных и сервисов, включая API графа корпоративных знаний с открытым исходным кодом, набор данных PyKEEN, Wikidata и т. д.
7. Режим куста агентов
Модель архитектуры куста агентов использует большое количество агентов ИИ, которые работают вместе для решения проблемы, и каждый агент вносит свой вклад со своей уникальной точки зрения.
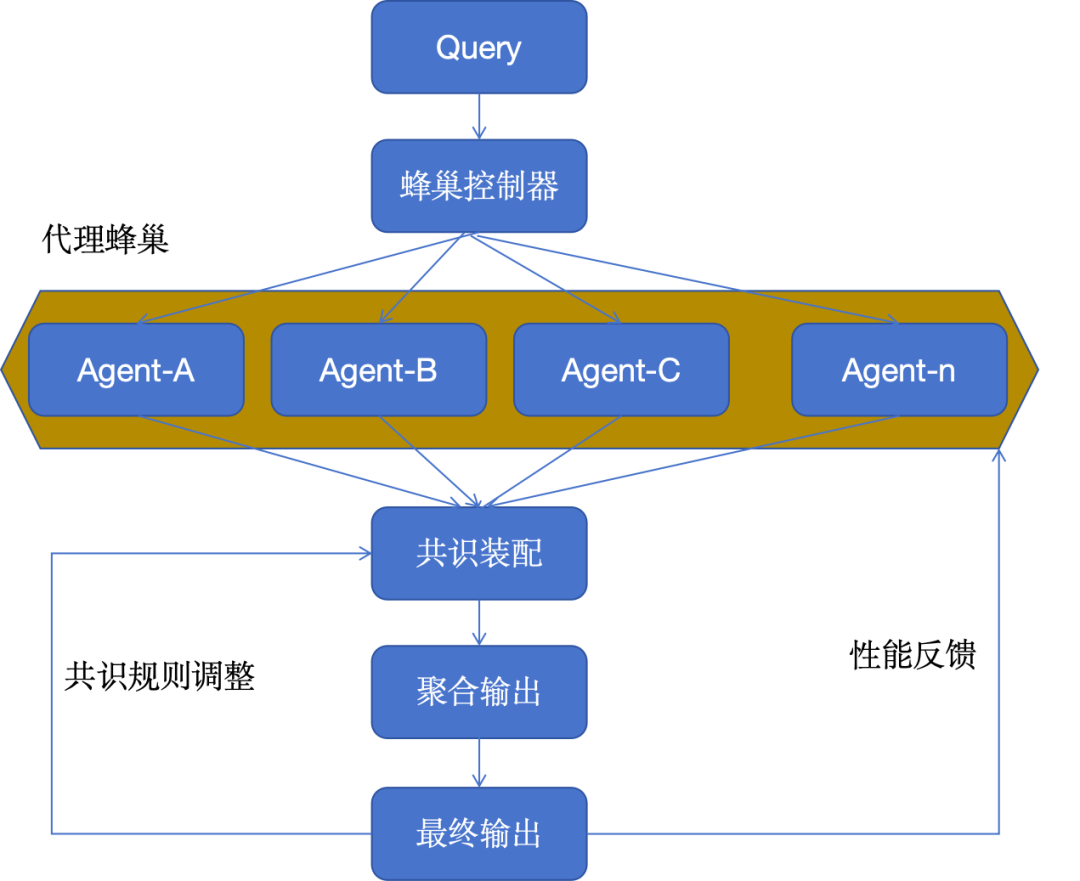
Полученные совокупные результаты демонстрируют коллективный разум, превосходящий то, чего может достичь любой отдельный ИИ в одиночку. Этот режим особенно эффективен в сценариях, требующих большого количества инновационных решений или при работе со сложными наборами данных.
Например, мы можем использовать несколько агентов ИИ для совместного рассмотрения исследовательской работы и интеграции всех их данных и мнений. Для систем ульев с более высокими требованиями к вычислительной мощности мы можем рассмотреть возможность развертывания служб очереди сообщений, таких как Apache Kafka, чтобы лучше обрабатывать доставку сообщений между брокерами и службами.
8. Режим комбинирования агентов
Эта архитектурная модель подчеркивает гибкость благодаря модульным системам искусственного интеллекта, которые могут переконфигурироваться для оптимизации выполнения задач. Это похоже на многофункциональный инструмент, который может выбирать и активировать различные функциональные модули в соответствии с потребностями, что очень эффективно для предприятий, которым необходимо настраивать решения для различных потребностей клиентов или потребностей продукта.
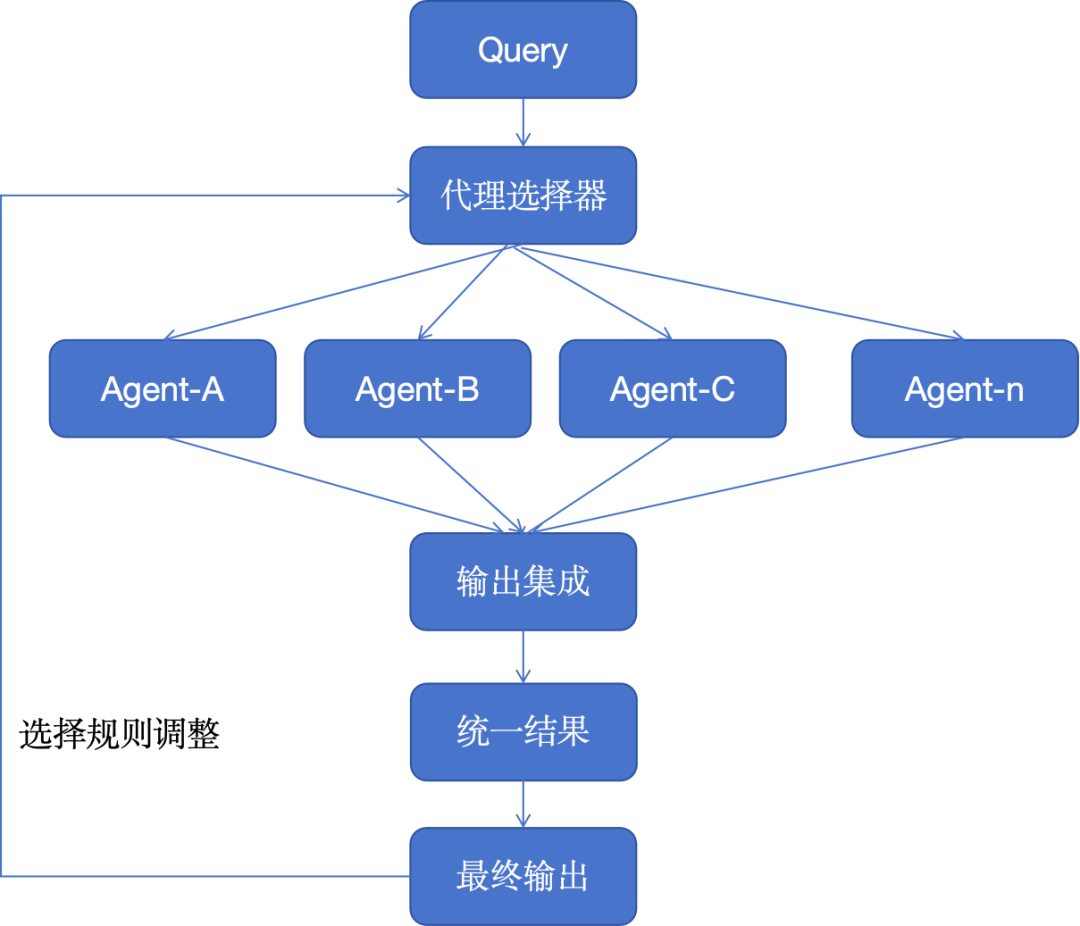
Мы можем разрабатывать каждого агента и его инструменты, используя различные платформы и архитектуры автономных агентов, такие как CrewAI, Langchain, LLamaIndex, Microsoft Autogen, superAGI и т. д.
Например, объединяя различные модули, один агент может сосредоточиться на прогнозировании, другой — на обработке запросов на резервирование, третий — на генерации сообщений, а последний агент может обновлять базу данных. В будущем, когда количество конкретных услуг, предоставляемых профессиональными компаниями в области искусственного интеллекта, увеличится, мы сможем заменить модуль внешним или сторонним сервисом для решения конкретных задач или проблем предметной области.
9. Когнитивная модель памяти.
Эта архитектура привносит в ИИ элемент человеческой памяти, позволяя моделям вспоминать и учиться на основе прошлых взаимодействий, что приводит к более тонким ответам.

Это полезно для постоянных разговоров или сценариев обучения, где ИИ со временем развивает более глубокое понимание, подобно профессиональному личному помощнику или онлайн-платформе машинного обучения. Со временем когнитивная модель памяти может суммировать и сохранять ключевые события в векторной базе данных, что еще больше обогащает систему RAG.
Чтобы сохранить разумный объем агрегирующих вычислений, мы можем выполнять агрегацию и суммирование, используя меньшие библиотеки обработки естественного языка. База данных векторов используется и извлекается на этапе подсказки для проверки кратковременной памяти и определения ключевых «фактов» посредством поиска ближайшего соседа. Одним из решений с открытым исходным кодом, которое следует этому шаблону, является MemGPT.
10. Режим двойной безопасности.
Основная безопасность больших языковых моделей (LLM) состоит как минимум из двух ключевых компонентов: пользовательского компонента, который мы называем пользовательским прокси, и межсетевого экрана, который обеспечивает уровень защиты модели.
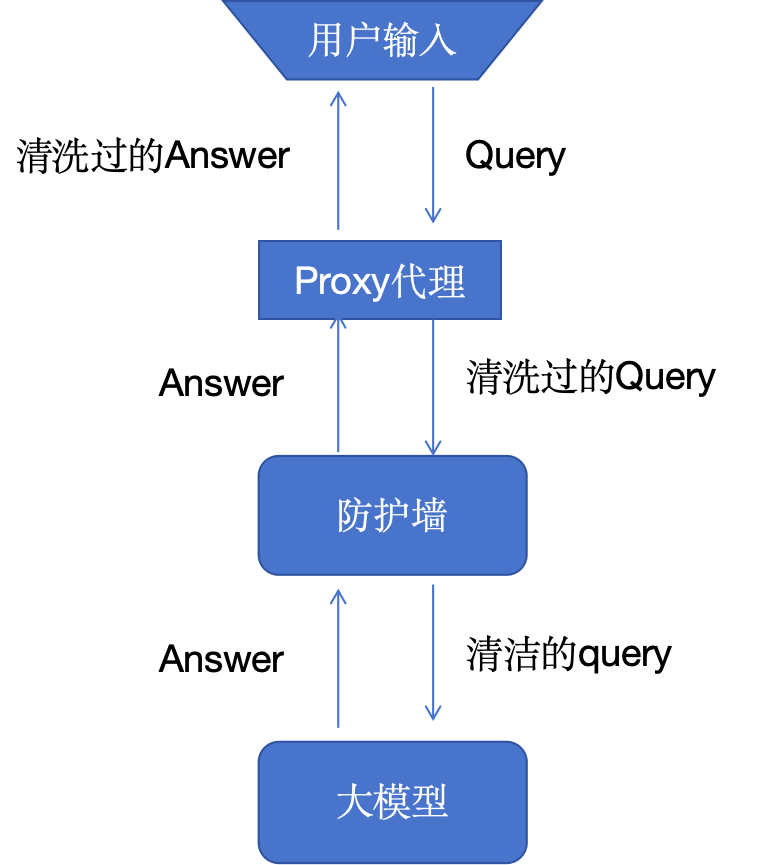
Пользовательский прокси перехватывает запрос пользователя в процессе выдачи и возврата запроса. Агент отвечает за очистку личной информации (PII) и информации об интеллектуальной собственности (IP), регистрацию содержимого запросов и оптимизацию затрат.
Брандмауэры защищают модель и используемую ею инфраструктуру. Хотя мы очень мало знаем о том, как люди манипулируют моделями, чтобы раскрыть лежащие в их основе данные обучения, потенциальные возможности и современное вредоносное поведение, мы знаем, что эти мощные модели уязвимы.
В стеке технологий, связанных с безопасностью, могут быть и другие уровни безопасности, но для пути запроса пользователя наиболее важными являются прокси-агенты и межсетевые экраны.
нет конца
Программисты-ветераны считают, что архитектурные шаблоны этих приложений с большими моделями — это не просто парадигма, но, вероятно, станут основой, на которой будут расти будущие интеллектуальные системы. По мере того, как мы продолжаем исследовать и внедрять инновации, появится множество новых архитектурных шаблонов, и представленные здесь 10 архитектурных шаблонов и вновь возникающие архитектурные шаблоны могут стать проявлением услуг искусственного интеллекта.
20 лет назад,когда я впервые прочитал《шаблон проектирования》Когда пишу книгу(Видеть《Три книги влияют на одного человека》одно предложение),Не могу отложить это,сейчас,Старые программисты начали продолжать изучать и практиковать приложения ИИ.,Они в этой статьеархитектурные узоры назвал сам опытный программист. Поправьте меня, если что-то не так. Я надеюсь продолжать обновлять эту серию, а также надеюсь, что друзья, которые заинтересованы в этом, смогут связаться со мной. Совместно исследуйте и изучайте архитектурные шаблоны, предназначенные для приложений с большими моделями.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
